書式
2 列: x-position y-value
3 列: x-position y-value boxwidth
4 列: first-x-position y-value boxwidth category
例
#
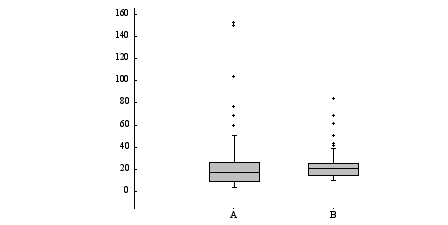
# 2 つの異なるファイルからの y 値の分布の比較
set border 2 # 左境界線のみ
set xtics nomirror scale 0 # 目盛り刻み無し、ラベルのみ
set ytics rangelimited nomirror
plot 'dataset_A' using (1.):2:xticlabel('A') with boxplot, \
'dataset_B' using (2.):2:xticlabel('B') with boxplot
#
# 同じファイル内の 2 つのデータカテゴリの y 値の比較
# 各行の 1 列目にはカテゴリを示す文字列 ("A" か "B")、2 列目にデ
# ータ値が含まれ、ラベルはカテゴリ文字列から自動生成する
start_x = 1.0
boxwidth = 0.5
plot 'mixeddata' using (start_x):2:(boxwidth):1 with boxplot
デフォルトでは、using で第 2 フィールドに指定した列のすべての y の値か ら、ただ 1 つの boxplot を生成します。もし using で第 4 フィールドを 指定した場合は、その入力列の内容は個別のカテゴリを識別するための文字列 として使います。入力列にある個々のカテゴリに対して、別な boxplot を描 画します。それらの boxplot 間の水平間隔は、デフォルトでは 1.0 ですが、 それは set style boxplot separation で変更できます。デフォルトでは、 カテゴリ識別子は、各 boxplot の下の目盛りラベルとして書きます。 もしカテゴリ列に数値が含まれていても、それはやはりあくまで文字列として 扱われるので、boxplot x 座標には通常は対応しません。
入力ファイル内のデータ点の順序は重要ではありません。データ点が入力ファ イル内で 2 行の空行で分離される複数のブロックになっている場合は、個々 のブロックはキーワード index で選択するか、またはデータブロック番号 (column(-2)) を第 4 列のレベル値として使用することができます。以下 参照: pseudocolumns (100.3.11.3), index (100.3.6)。
デフォルトでは箱ひげは、箱の端から、y の値が四分位範囲の 1.5 倍以内で 最も離れているような点まで延長します。外れ値は、デフォルトでは円 (point type 7) で描きます。箱ひげの端の棒の幅は、set bars か set errorbars で制御できます。複数の外れ値が同じ y の値を持つ場合、 水平方向に 1 文字幅分ずらしますが、その間隔は、set jitter で制御でき ます。
これらのデフォルトの性質は set style boxplot コマンドで変更できます。 以下参照: set style boxplot (113.86.2), bars (113.28), boxwidth (113.7), fillstyle (113.86.4), candlesticks (40)。
竹野茂治@新潟工科大学