最新の開発版 (git) の all.dem の出力を置いておきます。
- all.dem の PDF 出力 (2021-11-26 の GIT 版)
all-current-20211207.pdf (732 ページ、21,826,844 Byte) - その画像を小さくした一覧 (2021-11-26 の GIT 版)
all-20211207-list.pdf (13 ページ、31,784,980 Byte)
「情報やメモ (08/27 2021)」 の時点でのデモ (729 ページ) に比べると、 今回新たに追加された mask_pm3d.dem の分のデモ (58,59,60 ページ) が追加されています。
mask 機能 (plot with mask, mask キーワード) は今回あらたに追加された機能で、 画面上のある領域を定義するデータで、 後のグラフのその表示領域部分をマスク (隠す) ことができます。 convexhull とあわせて使用することもできるようです。
他には、以下のものが新規に追加されています。
- linetype nodraw
- set pm3d border retrace
- set palette viridis
- set style histogram nokeyseparators
いずれもそれほど「はなばなしい」ものというわけではないと思いますので、 詳しくはそれぞれのマニュアルをご覧ください。
(cf. 「情報やメモ (02/28 2022)」)
最新の開発版 (git) の all.dem の出力を置いておきます。
- all.dem の PDF 出力 (2021-08-26 の GIT 版)
all-current-20210826.pdf (729 ページ、20,748,433 Byte) - その画像を小さくした一覧 (2021-08-26 の GIT 版)
all-20210826-list.pdf (13 ページ、31,030,857 Byte)
「情報やメモ (07/29 2021)」 の時点でのデモ (726 ページ) に比べると、 今回新たに追加された convex_hull.dem の分のデモ (55,56,57 ページ) が追加されています。
convexhull キーワードは今回開発版にあらたに追加された機能で、 デモをみればわかりますが、データ点を全部中に含むような凸包 (最小凸集合) を描画します。通常は、多角形ですが、 smooth convexhull と指定することで平滑化することもでき、 また expand オプションで、全部の点が含まれるように少し広げることもできます。 主に、with filledcurve や with lines で書くことを前提としているようです。 実際には convexhull は、データの前処理機能で、 データ全部を使うのではなく、 その凸包の頂点を構成する点だけ取り出し、 それが閉曲線になるように、始点と終点は一致するようにする、 という仕組みになっているようです。
(cf. 「情報やメモ (12/07 2021)」)
だいぶ前に、日本地図データを作成し、 各都道府県の人口データのようなものを色で表現したグラフを紹介しました (「情報やメモ (03/26 2007)」)。 今回もそのようなグラフの一例を紹介します。
現在の gnuplot (今回は gnuplot-5.4.2 でやりましたが、 多分 gnuplot-5.2 以降なら OK) では、do for による繰り返しが使えるので、 必要な awk スクリプトとデータを用意しておけば、 データの前処理を awk で行いながら gnuplot で処理をする、 という作業が gnuplot から行えるようになっています。 早速サンプルグラフを以下に示します。 グラフは、最近 30 日間の、新型ウィルス新規感染者数の、 人口比の都道府県毎のグラフになっています。 PDF ファイルの方が全 30 ページで、画像はその先頭ページのサンプルです。
- 新規感染者数の人口比の都道府県毎のグラフ no.1 (色 1):
test15-1-c1.pdf
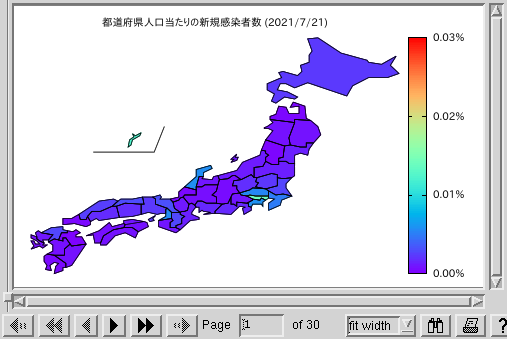
- 新規感染者数の人口比の都道府県毎のグラフ no.2 (色 2):
test15-1-c2.pdf
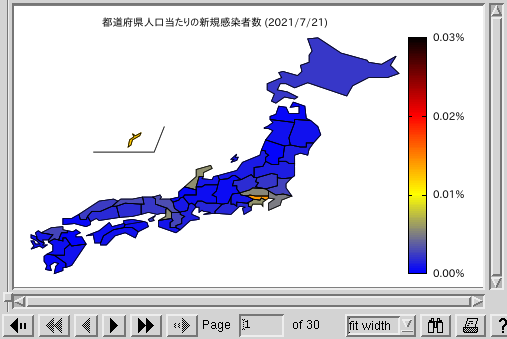
no.1 の方のパレットは標準的な rgbformulae 33,13,10 を使っていますが、 これだとかなりさわやかな色が表示されるので、 no.2 の方は自前で定義したグラデーションパレット (青-黄-赤-黒) を使っています。青、黄、赤は信号をイメージして、 さらにそれよりひどいものを黒という形で表現しています。
日毎の新規感染者数の都道府県別データは、 以下の NHK のデータを利用しています。
- NHK 新型コロナウイルス特設サイト:
https://www3.nhk.or.jp/news/special/coronavirus/
(「データのダウンロードはこちら」というところに以下のデータがあります: nhk_news_covid19_prefectures_daily_data.csv)
このデータは、UTF-8 の CSV データ ([年月日],[都道府県コード],[都道府県名], [新規感染者数],[累積感染者数],[新規死者数],[累積死者数]) ですが、 このデータから必要なものを取得して使っています。具体的には、
- このデータを EUC-JP のスペース区切りのデータ data1 に変換
- data1 から指定した日付のデータ (実際には最終日からさかのぼって n 日目のデータ) のみを標準出力に出力する awk スクリプト map-scr1.awk を用意
- 都道府県人口データ jinko.dat と 2. の出力を読み込んで、 都道府県番号と新規感染者数/都道府県人口 (%) のデータを標準出力に出力する awk スクリプト map-scr2.awk を用意
のようなスクリプトを用意した上で、gnuplot にグラフを書かせています。 前に紹介した日本地図グラフでは、plot 部分は gnuplot のコードを吐かせる awk スクリプト maptest2.awk を使って、 「load "< awk -f maptest2.awk data"」 のようなことをやっていましたが、 plot for と配列と stats が使える現在の gnuplot では必要ありません。 実際の gnuplot のコードは以下のようなものです。
unset key
unset border
unset xtics
unset ytics
#set palette rgbformulae 33,13,10
set palette defined ( 0 "blue", 1 "yellow",
2 "red", 3 "black" )
set cbrange [0:0.03]
set format cb "%.2f%%"
set cbtics 0, 0.01
set term pdfcairo
#set out "test15-1-c1.pdf"
set out "test15-1-c2.pdf"
array H[47] # 都道府県データの保存配列
do for [j=1:N] {
k = N + 1 - j
# k 日前のデータの抜き出し
system(sprintf("awk -f map-scr1.awk -v n=%d data1
> data2", k))
# 日付の取得
ts = system("awk 'NR==1{ print $1 }' data2")
# グラフ用データの作成
system("awk -f map-scr2.awk jinko.dat data2
> data3")
# グラフの値を配列に読み込み
k=0
stats "data3" using 1:(k=k+1,H[k]=$2,$2) noout
set title sprintf("都道府県人口当たりの新規感染者数
(%s)", ts)
print ts
plot for [k=1:47] "japan_map.dat"
index k-1 w filledc c not lt palette cb H[k], \
"" w l not lt -1
}
set out
なお、map-scr1.awk は、stats を使えば同様のことを gnuplot 内部でできますし、 map-scr2.awk も、jinko.dat のデータを stats で配列に取得してしまえば、 必要ありません。その改良版は以下の通りです。
unset key
unset border
unset xtics
unset ytics
#set palette rgbformulae 33,13,10
set palette defined ( 0 "blue", 1 "yellow",
2 "red", 3 "black" )
set cbrange [0:0.03]
set format cb "%.2f%%"
set cbtics 0, 0.01
set term pdfcairo
#set out "test15-1-c1.pdf"
set out "test15-1-c2.pdf"
# データ内の日数を取得
stats "data1" using 1 noout
Lines = STATS_records
dates = floor(Lines/47)
if (N > dates) exit
# 都道府県人口の取得 ([都道府県番号],[都道府県名],[人口(千人)])
array Pop[47]
stats "jinko.dat" using 1:(Pop[$1]=$3,$3) noout
# 都道府県データの保存配列
array H[47]
do for [j=1:N] {
k = N + 1 - j
system(sprintf("awk '(NR-2)%%%d == %d' data1
> data2", dates, dates - k))
# 日付の取得
ts = system("awk 'NR==1{ print $1 }' data2")
# グラフ用データを H[] に
k=0
stats "data2" using 1:(k=k+1,H[k]=$4/(Pop[k]*10),$4)
noout
set title sprintf("都道府県人口当たりの新規感染者数
(%s)", ts)
print ts
plot for [k=1:47] "japan_map.dat"
index k-1 w filledc c not lt palette cb H[k], \
"" w l not lt -1
}
set out
実は data1 の作成も nkf と sed でやっているだけですし、 NHK データの取得も wget でスクリプト化できます。 よって、それらも含めて単一のスクリプトのしてしまうことも可能です (少なくとも Unix 上では)。
「情報やメモ (07/30 2021)」 で報告した cairo-1.17.4 で pdfcairo を使った場合に 不正な pdf ファイルが作成される件ですが、 状況がわかりました。 これはやはり gnuplot ではなく、cairo-1.17.4 のバグでした。
x-cairo17-x.pdf と x-cairo16-x.pdf は良く見ると違うのは、 埋め込みフォントの名前だけで、以下のようになっています (less とかでも見れます)。
- x-cairo16-x.pdf (cairo-1.16.0):「FJLHRY+DejaVuSans」
- x-cairo17-x.pdf (cairo-1.17.4):「<86:0)+DejaVuSans」
PDF にフォントを埋め込む場合、 フォントファイルから必要なフォントだけを埋め込むので、 フォントファイルの部分集合名として [XXXXXX]+[元のフォント名] というフォント名を使うことになっていて、 この [XXXXXX] の部分は、大文字のアルファベット 6 文字とされています。 例えば以下に書かれています。
- Document management Portable document format Part 1: PDF 1.7
https://www.adobe.com/content/dam/acom/en/devnet/pdf/pdfs/PDF32000_2008.pdf (p258、9.6.4「Font subsets」)
それがなぜか 1.17.4 の方ではそれに合わない変な文字列になっていて、 そのため xpdf が正しく読み込めない、という問題のようでした。
cairo-1.16.0 と cairo-1.17.4 のソースを比較してみたところ、 src/cairo-pdf-surface.c にある _create_font_subset_tag() という関数に問題があることがわかりました。 ldiv() という long の割り算と余りを計算する関数を使って、 その 6 文字を生成しているのですが、ldiv() は負の数を割り算すると 負の余りを返すので、それが問題だったようです。すなわち、 上の変な文字列は、
- cairo-1.16.0:「FJLHRY」 = 'A'+5, 'A'+9, 'A'+7, 'A'+17, 'A'+24
- cairo-1.17.4:「<86:0)」 = 'A'-5, 'A'-9, 'A'-7, 'A'-17, 'A'-24
とやって作られていました。 cairo-1.16.0 では、割り算の前に abs() で正の数に直しているのに対し、 cairo-1.17.4 ではその abs() を取ってしまったために起きている問題でした。
cairo の方に報告しようと思ったのですが、 これは cairo の開発版 (git) では既に直っているようです。
- pdf font subset: Generate valid font names (2021-02-09)
https://gitlab.freedesktop.org/cairo/cairo/-/commits/master/src/cairo-pdf-surface.c
https://gitlab.freedesktop.org/cairo/cairo/-/commit/a3b69a0215fdface0fd5730872a4b3242d979dca
ということで、そのうちに cairo ライブラリも直っているものがでてくるでしょう。 それまでは、cairo-1.16 を使うか、 または cairo-1.17.4 に以下のパッチを当てて使えば良さそうです。
- cairo-pdf-1174-1.diff (644 Byte)
とりあえず今のところこのパッチで問題ないようです。
昨日 pdf ファイルのサンプル画像を作っていて気がついたのですが、 私の使っているマシン (FreeBSD 13) で最近 cairo library を 1.16.0 から 1.17.4 に更新したところ、 gnuplot の pdfcairo terminal で不正 (?) な pdf ファイルが できてしまうようになりました。 従来の cairo library だと問題はありませんし、 cairo-1.17.4 でも、文字が一切含まれない画像の場合も問題はありません。
- t-cairo17-x.pdf: cairo 1.17.4 での pdfcairo terminal の PDF 画像 (問題あり)
- t-cairo16-x.pdf: cairo 1.16.0 での pdfcairo terminal の PDF 画像 (問題なし)
いずれも、key のところに「x]という一文字だけ入った pdf 画像で、 gnuplot-5.4.1 で作成したものです。 1.17.4 の方は、xpdf で開くと大量のエラーメッセージが表示されます。
pdf ファイルを比較すると、/FontName のところだけが違っているようです。 gnuplot の問題というよりは、cairo library の問題なのかもしれません。 一応本家に報告しておきたいと思います。
(cf. 「情報やメモ (08/04 2021)」)
最新の開発版 (git) の all.dem の出力を置いておきます。
- all.dem の PDF 出力 (2021-07-28 の GIT 版)
all-current-20210730.pdf (726 ページ、20,734,705 Byte) - その画像を小さくした一覧 (2021-07-28 の GIT 版)
all-20210729-list.pdf (13 ページ、30,710,663 Byte)
「情報やメモ (04/30 2021)」 の時点でのデモ (724 ページ) に比べると、 507,508 ページのデモ (sparse matrix に対する heatmap) が追加されています。
sparse matrix は、matrix データの新たな形式で、 長方形の一様な格子を宣言した後で、 任意個のデータを任意の順でファイルから読み込んでその格子内に割り当てる、 というもので、格子全体にデータを割り当てる必要はない、というものです。 この demo の heatmap は全部が表示されていますが、 ドキュメントの heatmap のデモに付属する画像は、 データが上三角行列部分しか定義されていない sparse matrix のデータに対する heatmap の画像になっています。
(cf. 「情報やメモ (08/27 2021)」)
gnuplot の開発版で、配列に関する新しい機能がいくつか追加されました。
- 配列をユーザ定義関数の引数、および返り値にすることが可能に
- 部分文字列同様の書式で部分配列の指定が可能に
- 配列の要素を検索する関数 index(A, x) (A[i]=x となる i を返す) が追加
1. に対しては、ドキュメントには、内積を計算する以下の例があげられています。
dot(A,B) = (|A| != |B|) ? NaN : sum [i=1:|A|] A[i] * B[i]
2. に関しては、ドキュメントには以下の例が紹介されています。
array T = [ "A", "B", "C",
"D", "E", "F" ]
U = T[3:4]
# U の宣言は不要で、U = [ "C", "D" ] となる。
3. に関しては、x は、任意の数式、文字列が可能で、 型と値の両方が一致した場合に i を、なければ 0 を返すようになっています。 ドキュメントには、
array A = [ 4.0, 4, "4" ]
index(A, 4) は 2、
index(A, 2.+2.) は 1、
index(A, "D4"[2:2]) は 3 となる、
と記されています。
関数と配列を受け渡しすることで、 たくさんのデータの処理をサブルーチン化することが可能になるので、 かなり大掛かりなことができるような気がします。 例えば、シンプソンの公式とか、ルンゲ=クッタなどの 多くのデータに対する数値計算もそれでできそうです。
06/01 頃に gnuplot-5.4.2 が公開されました。 5.4.2 での新規機能、変更、修正は以下のようです。
- 新規: "using" 指定で現在の入力行の列数を意味する $#
- 新規: 起動時に虚数単位を定義: I = sqrt(-1) = {0.,1.}
- 新規: 疫学的な週、日付書式を使用する入力データのサポート
- 新規: "set key opaque" でオプションの fillcolor 指定
- 新規: uigamma 関数を与えるプラグインを使用する文書の提供
- 変更: igamma 関数の定義域と精度の大幅な改良
- 変更: マルチデータセット入力ファイル毎に key エントリを一つだけ生成 (#2380)
- 変更: (Windows): コマンドラインの Unicode を UTF-8 に変換するように
- 変更: 2 次元グラフで、`with image` を描画境界でクリッピングするように
- 変更: gprintf の書式 "%c" で、 前置がない場合空白を入れないように (#2266)
- 変更: 左の境界の自動配置をグラフのサイズにとらわれないように (#2415)
- 修正: 時刻書式 %U %W (#2390)
- 修正: cairo terminal: 複数行の拡張文字列処理でフォントを失わないように
- 修正: splot でユーザ指定の key 配置の、タイトルの左合わせ
- 修正: cairo terminal (Windows): 「文字の伸縮」でユーザスクリーン設定を無視
- 修正: win: ウィンドウサイズの変更に関連する不安定性 (#2301, #2304)
- 修正: pm: マウス操作とフォント処理の改善
- 修正: gnuplot_qt のゾンビプロセスの予防 (#2188)
- 修正: 2 個以下しか頂点を持たない閉多角形のクリッピング (#2400)
- 修正: "set tics front" が予期せずすべての格子線を不可視に
- 修正: textbox の境界の線幅指定をより多くの出力形式でサポート
- 修正: 単一入力ファイル内の、複数の行列データセットの番号付け
- 修正: 'set term' 後の入力ストリーム列に余計な '\n' を入れない (#2292)
新規の機能は、開発版から backport されたものなので、 特に目新しいものはありませんが、 リリース版で $#, I などが使えるようになったのはいいことだと思います。
Windows バイナリについてなのですが、相変わらず安定性が若干低いようで、 開発者のリリースアナウンスでも、以下のように述べられています。
On the other hand, there are known issues under Windows 105.4.2 の公式 Windows バイナリも、もしかしたらまた出ない可能性もあります。So Windows 10 users may want to stick with version 5.2 for now.
- Piped command input does not work reliably (Bugs #2204 #2412)
- Export to EMF file from toolbar may not work
When these problems are fixed I figure to put out a version 5.4.3 immediately that may be relevant only to Windows users.
all.dem は、5.4.1 からほぼ変わっていませんので、 5.4.2 用の all.dem の PDF 版は置かないことにします。
先日、gnuplot の開発版のページで見かけたのですが、
「show at」という、
マニュアルに載っていない仕様があることに気がつきました。
以下で、開発者の E.Merritt さんが使用しています。
- gnuplot sourceforge: Feature requests:
#521 Function definition lacks the capability to designate a 'local' variable
https://sourceforge.net/p/gnuplot/feature-requests/521/
調べてみると、バージョン 3.7 位から入っている (少なくとも 3.7.3 では使える) 機能でした。 多分数式の構文解析の確認用のものなので、 普段の gnuplot の利用で必要になることはほとんどないと思いますが、 もしかしたらデバッグ用、 開発用に開発者達が仕込んだ機能はこれ以外にもあるのかもしれません。
最新の開発版 (git) の all.dem の出力を置いておきます。
- all.dem の PDF 出力 (2021-04-28 の GIT 版)
all-current-20210430.pdf (724 ページ、20,768,500 Byte) - その画像を小さくした一覧 (2021-04-28 の GIT 版)
all-20210430-list.pdf (13 ページ、30,635,637 Byte)
「情報やメモ (02/01 2021)」 の時点でのデモ (722 ページ) に比べると、 537 ページ (平面ベクトル場のデモ)、 570 ページ (エラーバー付きのヒストグラム) のデモが追加されています。
なお、all.dem には追加されていませんが、 最近の GIT 開発版には複素変数、複素数値のリーマンゼータ関数 zeta(z) が追加され、 special_functions.dem には zeta.dem が追加されていて、 いわゆるリーマン予想を意識したデモなどが紹介されています。
- gnuplot demo script: zeta.dem
http://gnuplot.sourceforge.net/demo_5.5/zeta.html
(cf. 「情報やメモ (07/29 2021)」)
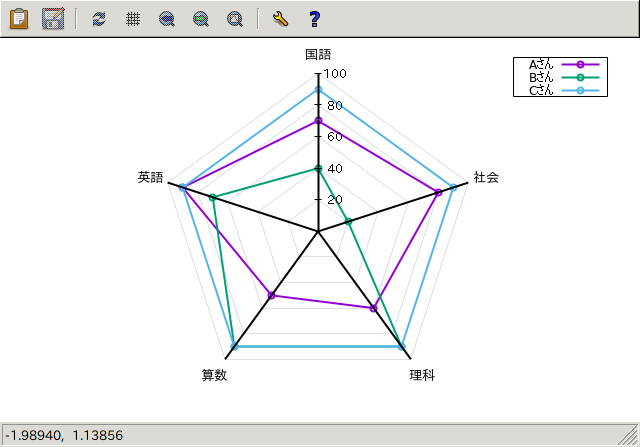
そういえば、最近導入された、レーダーチャート用の spiderplot について サンプルをあげてなかったので、簡単に紹介しておきます。 ちなみに、以前ここに書いたレーダーチャートの記事は以下のもので、 いずれも awk などを用いて自前で作成したものです。
- 「情報やメモ (01/29 2008)」: 一番最初に作ったもの。データの転置を awk で行い、 極座標 (set polar) を使って、 グラフや背景などを徐々に作り上げていくように紹介。
- 「情報やメモ (01/29 2015)」: レーダーチャート no.2。set for, plot for, do for (gnuplot 5.X) を使って 描画を多少楽に。ただし set polar は使わず、自前で座標を計算。 libgd の png terminal の問題も指摘。
- 「情報やメモ (03/29 2017; no.2)」: レーダーチャート no.3。no.2 のものを set polar で。 stats でデータの情報も調べている。
- 「情報やメモ (06/07 2017)」: レーダーチャート no.4。データの転置の際に、 先頭データを最後に追加せずに閉曲線を書くために、 every を使う方法と with filledcurve closed を使う方法を紹介したもの。
spiderplot (gnuplot 5.4) を使う場合は、 データの転置が必要ありませんので、 今回は以前のデータと同じもの:
生徒 国語 社会 理科 算数 英語を、gnuplot のインラインデータブロックとして記述して使用することにしますが、 もちろんファイルからのデータ入力でも構いません。
Aさん 70 80 60 50 90
Bさん 40 20 90 90 70
Cさん 90 90 90 90 90
set term wxt
##### インラインデータブロック
$data <<EOD
生徒 国語 社会 理科 算数 英語
Aさん 70 80 60 50 90
Bさん 40 20 90 90 70
Cさん 90 90 90 90 90
EOD
##### データの解析と名前の取得
stats $data every ::1 using 2 noout
M = STATS_records
N = STATS_columns - 1
array name[M]
i=0
stats $data every ::1 using 2:(i=i+1,name[i]=strcol(1)) noout
##### spiderplot の開始
set spiderplot
set style spiderplot lw 2 pt 6 ps 1
set for [i=1:N] paxis i range [0:100]
set paxis 1 tics font ",9"
set grid spider lt 1 lc "grey" lw 0.5 back
set key box at screen 0.95, 0.95 font ",9"
plot \
for [i=1:M] keyentry with lp lt i lw 2 pt 6
ps 1 title name[i],\
for [i=1:N] $data using i+1 title columnhead
- 上のコマンドの結果 (wxt terminal のスナップショット):
以下でスクリプトの説明をします。
- 途中、
statsでデータの解析を行っていますが (10 行目 ~ 15 行目)、 データの行数、列数が最初からわかっていればstatsを使う必要はありません。 わからない場合は上のようにstatsで解析ができます。 - 最初の
stats(10 行目) はデータの行数、 列数を取得するものですが、every ::1としているのは、 先頭行が文字列だけからなる行なので 先頭行を読み飛ばすために使用しています。 そうでないと、statsが警告を出します。 また、using 2としているのも、先頭列が文字列だからです。 - 11, 12 行目で行数、列数を M, N に取得していますが、
これは先頭行、先頭列を除いた行数、列数で、
よってこの場合は M = 3、N = 5 となります。
M には、
everyによって先頭行が読み飛ばされた行数が入ります。 - 2 回目の
stats(15 行目) は、 2 行目以降の先頭列の名前を配列 (name[ ]) に保存するために使っています。 spiderplot は、データを横に見て折れ線を結ぶので、title columnheadで正しい key を書くことができません。 よって、key をkeyentryで自作する必要があるのですが、 その際にこの名前配列を使用します。 なお、1 列目は文字列なので、「=$1」ではなく、 「=strcol(1)」とすることに注意してください。 - 17 行目は spiderplot 描画の宣言です。
- 18 行目の
set style spiderplotは、 レーダーチャートグラフの線や点の属性指定です。fillstyleを指定して レーダーチャート内部を塗り潰すことも可能です。 - 19 行目は、spiderplot での軸 (
paxis) の範囲指定です。 spiderplot は「parallel axis + set polar」という形で実現されているので、 各軸は「paxis <軸番号>」になります。 - 20 行目は、1 つめの
paxis軸 (= 真上向き) にだけ軸の刻みのラベルを入れるようにしています。 もちろんset forですべての軸にラベルを入れることも可能ですし、 2 番目以降の軸の刻みラベルを消すために、 明示的に「set for [i=2:N] paxis i tics format ""」 のようにすることも可能です。 - 21 行目は、spiderplot の格子線 (グレーの蜘蛛の巣線) の設定です。
実は、help document には「
set grid spiderplot」 の説明がありませんが、gnuplot-5.4 からこれが使えるようになっています (デモ spiderplot.dem にはある)。 - 22 行目は key の位置の指定です。 デフォルトは、グラフと重なる位置に書かれたりするので、 このように自前で位置を指定する必要がある場合があります。
- 23 行目から 25 行目がグラフの描画です。
24 行目の
forはkeyentryによる key の自作部分です。 spiderplot で key が必要な場合は、ほぼこの作業が必須です。 - 25 行目の
forは spiderplot の実際の描画で、using i+1としているのは、 名前である先頭列の次の列から、としているためです。title columnheadは、 これによりデータの先頭行にある科目名が それぞれの軸の先に書き出される、という仕組みになっています。 このこともそうですし、using指定の各列のデータが 線でつながれて描画されるのではないことも、 通常の plot とはだいぶ仕組みが違う plot であることがわかると思います (転置されているような形)。
spiderplot では、plot using i によって、
i 番目の列のデータが
i 番目の軸に書かれます。
例えば上の例では、
using 1+1 t columnheadによって、 2 列目の「国語 70 40 90」が読み出され、「国語」が title として 1 番目の軸 (真上向き) のラベルとして使われ、 70, 40, 90 がこの軸上のデータになり、using 2+1 t columnheadによって、 3 列目の「社会 80 20 90」が読み出され、「社会」が title として 2 番目の軸 (右上向き) のラベルとして使われ、 80, 20, 90 がこの軸上のデータになり、 1 番目の軸のデータと順番の lt で結ばれる
といったことになっていきます。 そして、spiderplot では最後の列のデータは、 最初のデータに自動的に結ばれます。
なお、今回の科目名は短いのでずらす必要性はそれほどありませんが、
科目名に相当する先頭行のそれぞれの名前が長い場合は、
デフォルトの title columnhead
で出される位置がグラフと重なってしまうことがあります。
その場合は、offset を使ってずらしてあげればいいでしょう:
labeloff(i) = (i==1) ? 0: (i==2) ? 1.2: (i==3) ? 0.6: (i==4) ? 0.4: 0.7
set for [i=1:N] paxis i label offset labeloff(i) font ",9"
前のやり方と比べて、 データの転置や、軸や蜘蛛の巣線を自前で作成したりする必要がない分 spiderplot の方がだいぶ楽ですが、 データの見方が少しわかりにくくなるし、 それなりにやることはあるかな、といったところでしょうか。
最近はまったこと 2 点について報告します。
- 「
unset raxis ; unset rtics」レーダーチャート用に、 「
unset raxis ; unset rtics」 としたら「unexpected or unrecognized token: unset」などと言われました。 2 つに分けてそれぞれを 1 行ずつで実行した場合は問題ありません。 gnuplot-5.2, 5.4, 5.5 (開発版) すべてで起こります。どうやらバグのようで、本家に報告したら修正されたようです。
- 「pngcairo と epscairo の単位」
色々テストしながらグラフを作成する場合、 見るときは pngcairo、LaTeX 文書に貼り込むときは epscairo、 などとすることが多いのですが、
とやってうまく表示されるようになったものを、そのままset term pngcairo size 480,400
とやったらえらいことになりました。 できた eps ファイルを gv で確認しようとしたら X がぶっとびました (FreeBSD 上の Xorg)。 メモリアロケーションエラーのようです。set term epscairo size 480,400eps ファイルの BoundingBox を見てようやく気がついたのですが、 epscairo の方は、size のデフォルトの単位は pt ではなく、 「インチ」になっていて、 よって 480inch x 400inch (= 12m x 10m) などという巨大なサイズの eps ができてしまったわけです。 正しくは、
のようにすべきでした。set term epscairo size 6.67,5.56とはいえ、その巨大 eps を gv で見ようとして X が落ちるのもどうかと思いますが、 そういう危険があることには注意が必要です。
最新の開発版 (git) のマニュアルの日本語訳を更新しましたが、 デモはほとんど更新されていませんでした。
最近の 開発版ですが、以下のような改変がありました。
- uigamma (上方不完全ガンマ関数) の追加
- $# で、入力データの現在行のデータ列数を取得できるように
- fit のエラー処理の改変
今まで、igamma(a,z) (=下方不完全ガンマ関数) はありましたが、 今回 uigamma(a,x) (=下方不完全ガンマ関数) が追加されました。 ただし、引数は、igamma が複素数対応なのに対して、uigamma は実数だけです。 なお、uigamma(a,x) = 1 - igamma(a,x) なのですが、 これで計算すると精度が良くない場合があるそうで、 それで別な実装が行われているようです。
$# は、AWK で言うところの NF に相当するもので、例えば
column($#) は最終列の数値、
stringcolumn($# - 1) は最終列の一つ手前の列の文字列
を指すことになります。
データの列数が不明な場合、あるいは列数が行毎に違いがあり、
後ろから指定する方が確実な場合などに便利だと思います。
fit のエラー処理は、従来はエラーが起きると スクリプトがそこで停止していたのかもしれませんが、 今回の改変でエラーが起きても常にスクリプトの次の行に進むようになり、 エラーが起きたかどうかは FIT_ERROR で判別できるようになりました。 これで、エラーが起きても止まらないようなスクリプトを書くことができます。 ドキュメントには、以下のような例が紹介されています。
do for [i=1:5] {
DATA = sprintf("Data_%05d.dat", i)
fit f(x) DATA via a,b,c
if (FIT_ERROR || !FIT_CONVERGED) {
continue
}
set output sprintf("dataset_%05.png", i)
plot DATA, f(x)
unset output
}
最新の開発版 (git) の all.dem の出力を置いておきます。
- all.dem の PDF 出力 (2021-02-01 の GIT 版)
all-current-20210201.pdf (722 ページ、21,575,025 Byte) - その画像を小さくした一覧 (2021-02-01 の GIT 版)
all-20210201-list.pdf (13 ページ、31,404,659 Byte)
「情報やメモ (11/04 2020)」 の時点でのデモ (806 ページ) とページ数がだいぶ違うことからわかるように、 デモにだいぶ出入りがあります。 ざっと比較したところ、以下のようになっているようです。
- 20210201.pdf の 221-223 (kdensity2d.dem), 491 (指数積分: expint.dem), 494 (Γ(x+iy): lnGamma.dem), 495-496 (igamma.dem), 706-707 (3D polygon: polygons.dem), 714 (palette+alpha.dem) ページのものが追加
- 20201104.pdf の 460-478 (グラデーションの見本: pm3dcolors.dem), 718 (3D polygon: polygons.dem), 733-806 (最後の断面アニメーション: voxel.dem) ページのものが削除
なお、今回から少しわかりやすいように、 all-YYYYMMDD-list.pdf の方には、ページ番号を端に入れるようにしています。
ちなみに、最近の GIT 開発版ですが、以下のような改変がありました。
- webp terminal の追加 (webp 形式の画像、またはアニメーションを出力)
- block terminal の追加 (dumb 同様テキスト文字出力、 ただし Unicode グラフィック文字を使った改良版)
- 週番号 %W, %U を ISO 8601 などに準拠させた形に改良
webp terminal は、描画は cairo+pango で行うようなので、 pngcairo 同様の画像ができると思います (未確認)。 gif 以外のあらたなアニメーションも出力できる出力形式です。
block.trm terminal は、Unicode のブロック要素 (U+2580-259F)、 または点字文字 (U+2800-28FF) を利用して、 少し解像度を上げる工夫をしているようです (未確認)。
週番号 %W,%U は、これまではあまり厳密なものではなかったようですが (さほど需要がなかった ?)、昨今の時勢に沿った改良で、 %W の方は ISO 8601 のルールに、%U も同様のルール (CDC/MMWR のルール) に従うようになったようです。 週単位のデータの表示には有用な改良だと思います。
(cf. 「情報やメモ (04/30 2021)」)