yomi WWW page (in Japanese)
- yomi とは
- yomi のサンプル
(03/31 2017 更新)
- 付属ツールのサンプル/スクリーンショット
(05/15 2019 更新)
- ダウンロード
(05/15 2019 更新)
- いくつかの情報
(05/15 2019 更新)
- yomi に関する Q and A
(08/09 2010 更新)
- 謝辞
(07/13 2009 更新)
- 関連サイト
(04/25 2004 更新)
UNIX のページへ戻る
yomi は、UNIX 上の日本語テキストファイル読み上げを行うフリーソフトです。
基本的にごく単純な方法で動作しているため、非常に低品質、低機能です。
現在の最新版は
yomi Version 0.18.1 (05/15 2019 現在)
です。
詳しくは
付属のドキュメント
をご覧下さい。
ご意見、ご感想等は こちら へ
お願いいたします。
目次へ
yomi は、基本的に 1 行ずつの音声ファイルを作成し、それを音声出力します。
以下にいくつかその 1 行の例を示します。
サンプルファイルは .au (8bit μ-Law 8kHz) 形式、および .wav (linear 8kHz)
です (yomi は version 0.6 より WAV、version 0.8 より AIFF も support
しています)。
以下のサンプルを聞けば、yomi がいかに低品質であるか、そして、
いくつかの問題点を持っていることがわかると思います。
「こえうぇぶ」の
音素などを使用する場合は、音素の前後の空白を削除する必要があります。
また、ファイルサイズが大きい場合は、実行環境によっては、
適当に品質を落してサイズを小さくする必要もでてくるでしょう。
単にその音素を使用した場合のサンプルを次に示します。
サンプルファイルは、「こえうぇぶ」のファイル (AIFF) を、
サンプリング周波数を変えずに WAV (16bit linear 48kHz) にしたもの、および、
sox (12.16) を使って AU (8bit μ-Law 8kHz) にしたものを使用しています。
いずれも空白の削除、音素の長さの調整は行っていません。
AU ファイルの方は、「が」の音に雑音が入っているのがわかると思いますが、
これはダイナミックレンジの問題で、
データの変換時にそれを絞れば解消できるようです。
次の例は、AU ファイルに対しては、その「が」の雑音を取り、
音声データの前に存在する空白部分を取り、
データファイルの長さを揃えたものを使用したものです。
データファイルは AU (8bit μ-Law 8kHz) と WAV (16bit linear 48kHz) です。
長さを揃えるのには、yomi 付属のツール ausubstr, wavsubstr を使用しました。
各音素の長さは、0.25 秒にしたもの、0.18 秒にしたものの
2 種類ずつの例をあげます。
このように音素の長さを変えることで、早口を実現できます。
なお、yomi version 0.7 より、読みの速度の調整は、
音素の長さを変えておかなくても、yomi 実行時にオプションを指定することで
できるようになりました。
また、version 0.17 より、各音素の出だしと終わりを連続的に
0 に変化させることで音素を柔らかく連結するオプション (-C, -D)
を追加しました。
元々の音素の出だしと終わりが 0 に近ければあまり意味はありませんが、
単音データのようなものを連結する場合は、
単純に連結するとつなぎ目にノイズが発生しますが、
このオプションにより多少それを減らすことができます。
以下に、「-Cs10 -Ds100」(先頭は 10 ミリ秒 0 からクレッシェンド、
末尾は 100 ミリ秒 0 へデクレッシェンド)
のオプションを使った例を紹介します。
最初の言葉のデータの場合には、元々出だしと終わりが 0 に近い状態なので、
それほど違いはわかりません。
むしろ、後者の方が減衰オプションのせいで少し聞きにくいかもしれません。
一方、単純音の方は違いがよくわかると思います。
後者は「休符」や「息つぎ」を入れるようなものになるので、
必ずしも後者が前者に勝るわけではありませんが、
つなぎめのノイズが気になる場合はそれを消すことができる、
ということの原理がわかると思います。
目次へ
-
音声切り出しソフト auslcut のスクリーンショット
(08/12 2001 更新)
-
簡単な音声波形作成ソフト mksnd1.tcl のスクリーンショット
(01/05 2005 更新)
-
グリッサンド音生成ツール sndglis のサンプル
(08/23 2005 更新)
-
gnuplot グラフの音声化ツール tbl2snd のサンプル
(08/29 2005 更新)
-
紙のソーティング補助ツール sortejun のサンプル
(01/13 2007 更新)
-
聴覚周波数検査デモスクリプト earch.csh
(01/13 2007 更新)
-
無限音階 (sndglis, sndcresc によるサンプル)
(05/02 2008 更新)
-
DTMF 信号 (プッシュホン信号; sndhz, sndmix, wavconn によるサンプル)
(06/12 2009 更新)
-
shless と awk による読み合わせのサンプル
(05/15 2019 更新)
(08/12 2001 更新)
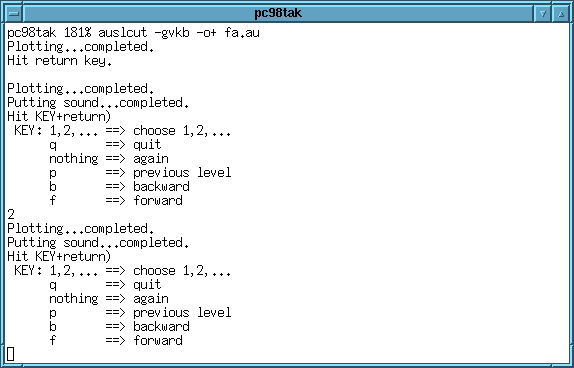
auslcut は、グラフィックモードを使うと
音声ファイルを gnuplot のグラフで確認しながら切り出しができます。
そのスクリーンショットを作ってみました。
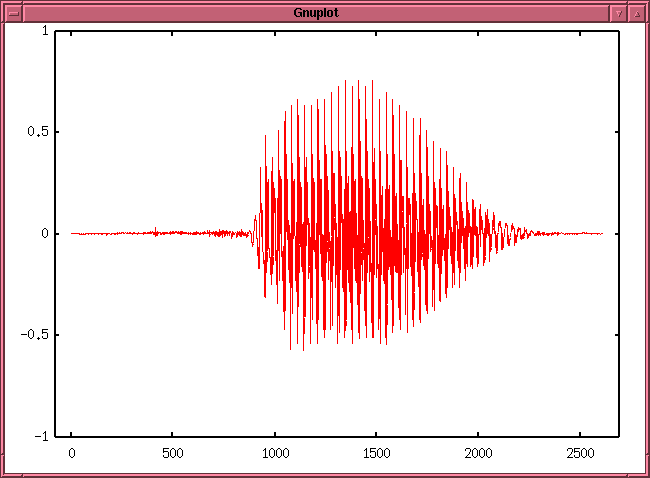
- まず、auslcut を
auslcut -gvkb -o+ fa.au
と起動した所の kterm と、
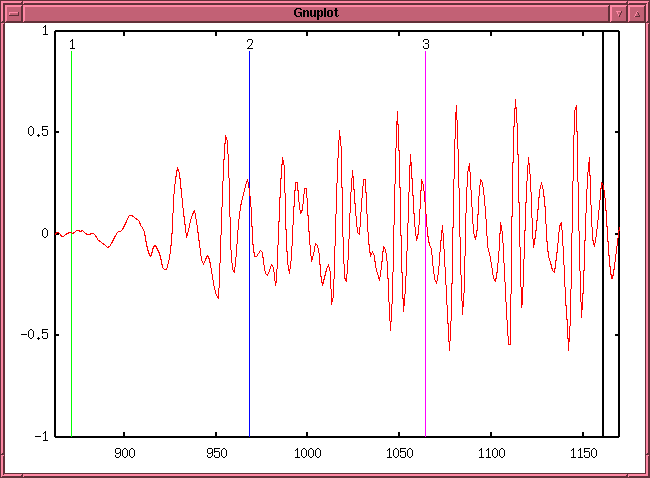
それによって立ち上がる初期の gnuplot のグラフです。
- そこで Return を押すと、gnuplot の画面に、切り出し位置を示す線が出て、
それぞれの線から切り出した音声がスピーカーに出力され、
どれを選択するかを聞いて来ます。
3 等分に見えますが、実際には一番最後のもの (黒からの切り出し)
も出力するので 音声が 4 回出力されます。
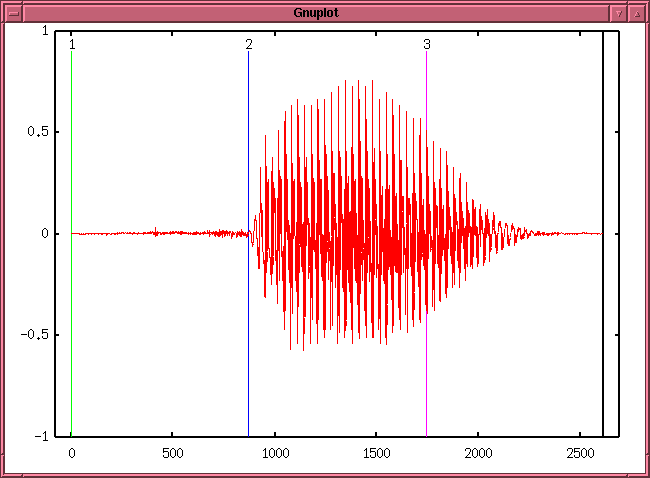
- 2 (青い線) の位置を選択して Return を押すと、
今度は 2 から 3 の間が拡大表示され、そこを 3 分割した切り出し位置での
音が出力されます。

- さらに 1 (先頭の緑の線) の位置を選択して Return を押したものです。
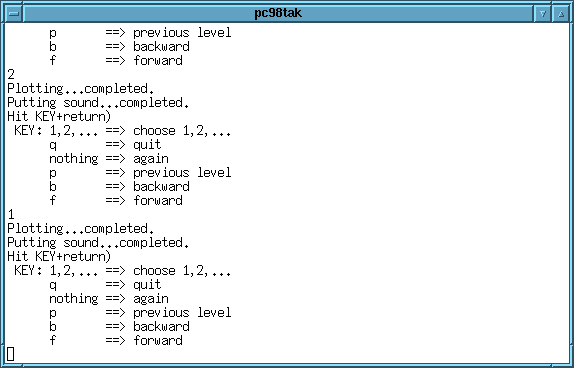
- これを続けていって、q を選択するか、あるいは選択幅が狭くなりすぎたと
見なされた所で終了します。
以下は、選択幅が狭くなりすぎた状態です。
gnuplot のグラフは自動的に消えます。
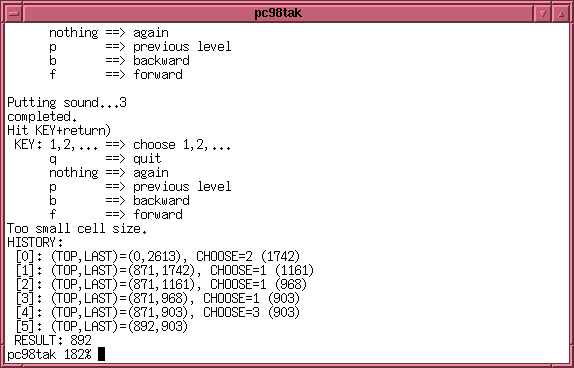
"HISTORY" 以下に何が選択されて、
その位置はどこかが出力されています。
au file なので単位は 1/8000 秒です。
そして、最終的な切り出し位置は "RESULT: 892" と得られています。
実際の切り出しは、
ausubstr 892 fa.au > fa-new.au
でできます。
目次へ
(01/05 2005 更新)
mksnd1.tcl は、大学のオープンキャンパスの模擬実験でも使用した、
GUI の音声波形作成ソフトです。
yomi version 0.13.3 より yomi に含まれています。
その簡単なスクリーンショットを作ってみました。
- まず、mksnd1.tcl を、オプションをつけずに単に起動した画面です。
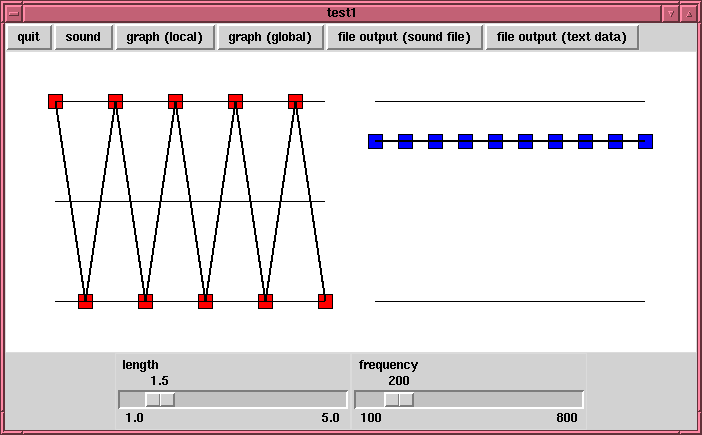
左の赤い方が基本波形の編集画面、右の青い方が包絡線の編集画面です。
下のスライダは、出力長 (秒数) と出力音声 (周波数) の指定です。
- 赤い四角、青い四角をマウスで上下に移動して
基本波形と包絡線を編集します。
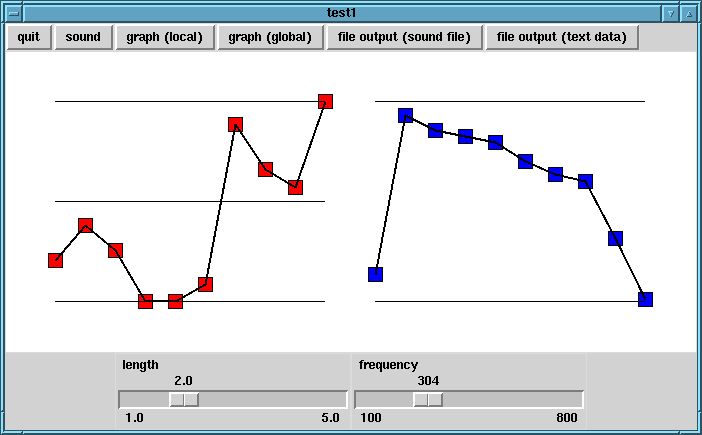
- graph メニューをクリックすると、
音声データを gnuplot でグラフ表示します。
"graph (local)" の方は拡大した様子で、基本波形が見て取れます。
"graph (global)" の方は全体のグラフで、包絡線形が見て取れます。
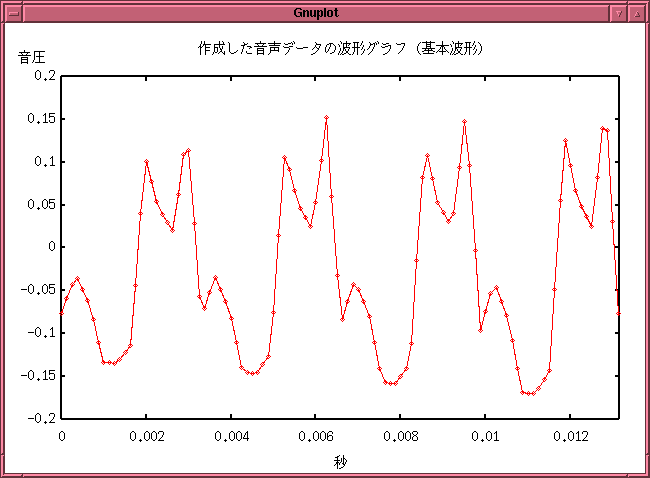
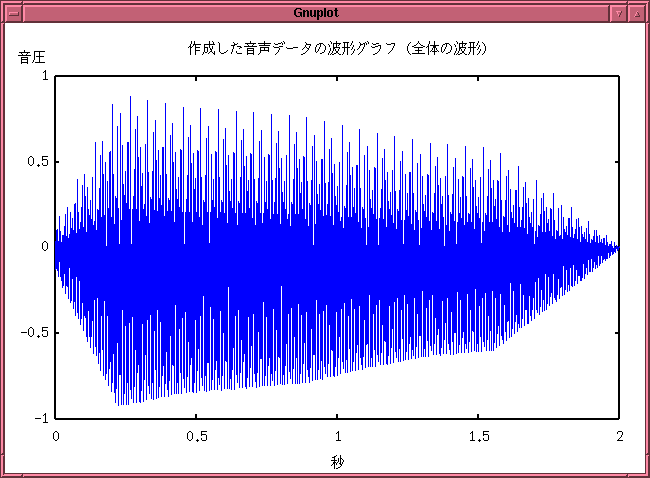
- "sound" メニューをクリックすると、
現在編集中の音声が鳴ります。
ちなみに、上の例の場合は以下のような音が出ます。
これは、グラフの見た目よりも素直な音だったみたいです。
目次へ
(08/23 2005 更新)
sndglis はグリッサンド音を生成するお遊びツールですが、
現在、これを改良したものを別な目的で利用することを考えています。
それと関連して、2 つ程簡単なサンプルを作ったのでここに置いておきます
(サンプリング 11025Hz, 16bit linear WAV file)。
なお、これらは sndglist と sndmix でそれぞれ以下のようにして作りました。
- glis1.wav:
sndglis -wav A0 A1 5000 > hoge1.wav
sndglis -wav A1 A0 5000 > hoge2.wav
sndmix -lg0.5 hoge1.wav -lg0.5 hoge2.wav > glis1.wav
- glis2.wav:
sndglis -wav A0 A1 5000 > hoge1.wav
sndglis -wav C#1 C#2 5000 > hoge2.wav
sndglis -wav E1 E2 5000 > hoge3.wav
sndmix -lg0.3 hoge1.wav -lg0.3 hoge2.wav -lg0.3 hoge3.wav > glis2.wav
- glis3.wav:
sndglis -wav A0 E2 5000 > hoge1.wav
sndglis -wav C#1 C#2 5000 > hoge2.wav
sndglis -wav E1 A1 5000 > hoge3.wav
sndmix -lg0.3 hoge1.wav -lg0.3 hoge2.wav -lg0.3 hoge3.wav > glis3.wav
目次へ
(08/24 2005, 08/29 2005 更新)
上の
「グリッサンド音生成ツール sndglis のサンプル」
のところにも少し書きましたが、
現在、sndglis を少し改良した tbl2snd というツールを作っています。
これは、gnuplot の table 出力を音声化するもので、
音程の高低でグラフの高低を表します。
sndmix, sndstereo と組み合わせることで、
複数のグラフを同時に音声化することも可能です
(これは現在 tbl2snd だけでできるようにもするか検討中です)。
まだ作成途中ですが、サンプルをいくつか作ってみましたので、
それを先に公開します
(サンプリング 11025Hz, 16bit linear WAV file、いずれも 5 秒)。
- y=x と y=x*x のグラフ (0≦x≦1)
- y=sin(x) と y=cos(x) のグラフ (-10≦x≦10)
y=x と y=x*x の方は、最初と最後のところで音程が等しくなるので、
単純に合成するとその付近でうなりが発生しているのがわかると思います。
一方の波形を変えると多少うなりは聞こえにくくなりますが、それでも
やはり多少聞こえます。
ステレオに分離するとうなりはなくなるようです。
(08/24 2005)
tbl2snd がほぼできましたので、
yomi-0.13.4 に tbl2snd を付属させました。
上のサンプルは table データからそれぞれ以下のようにして作れます。
tbl2snd -wav -u2 file.tbl > tbl-1.wav
tbl2snd -wav file.tbl > tbl-2.wav
tbl2snd -wav -m2 -u2 file.tbl > tbl-3.wav
tbl2snd -wav -m2 file.tbl > tbl-4.wav
table データ (file.tbl) は、
gnuplot に以下のような命令を食わせればできます。
set term table
set out "file.tbl"
plot [0:1][0:1] x, x*x
set out
(08/29 2005)
目次へ
(01/13 2007 更新)
sortejun は、テスト用紙などのように番号の書かれた紙を
ソーティングするときに補助となるツールです。
詳しくは
「いくつかの情報 (yomi version 0.13.8)」
を参照してください。
現在、採点の済んだテスト用紙のソーティングに実際に利用しています。
普通は、テスト用紙のデータをコンピュータに入力する「前」にソーティングして、
学生番号順に入力していくんだろうと思いますが、
私は、データの入力時はバラバラの紙のデータを、学生番号も一緒に入力します。
それは、以下のような理由によります。
- 学生番号は、欠席者や、履修していない人もいるので必ずしも連続していない
- 採点のときは、特定の順に採点するよりも、
それとは無関係に答案を分離した方が効率が上がる
(例えばほとんど書いてない答案と、ギッシリ書いてある答案を分けるとか)
- 学生番号の入力も、片手で入力できるように、
そのときだけ emacs のキー配置を変えるモード (自作) を利用している
- データや紙のソーティングは、コンピュータに考えてもらう方が楽
よって、答案用紙がどのように並んでいるか、
という情報がコンピュータにあるので、
それを利用して最後にソーティングを行います
(ソーティングしなければいけない理由は、
学生への答案の返却の際はその方が便利なため等)。
そのソーティングの例をここで紹介します。
実際の 80 人位のデータを紹介するのは大変なので、
上から順に次のように並んだ、10 枚の架空の学生番号のついた答案を使います。
2005a051
2005a018
2005a074
2005a093
2005a047
2005a041
2004c056
2005a073
2005c037
2005a069
このようなデータ (1 行に学生番号 1 つがあるデータ)
が書かれたテキストファイルを data.txt とし、
ソートは、紙を表にしたまま、3 つの山 (左から 1,2,3 番の山)
に配っていくことでソーティングをすることにします。
この場合、sortejun を
sortejun -I2 -o3 < data.txt > data.srt
(I2 = 文字列としてソート, o3 = shless 用の出力を行う)
と実行すると、shless 用の出力ファイル data.srt が作成されます。
これを
shless -c +v +l data.srt
shless にかけて実行すると、
[1 回目開始]
と表示され、
と音声ガイドが流れます。
return キーを入力すると、最初の 5 枚に対して (デフォルトでは 5 枚ずつ止まる)
[2005a051 --> 1]
[2005a018 --> 1]
[2005a074 --> 1]
[2005a093 --> 1]
[2005a047 --> 2]
と表示され、
と音声ガイドが流れます。
これに従って紙を上から順に 1,1,1,1,2 の山に配ります。
つまり、これにより、
- 1 の山 (上から): 2005a093, 2005a074, 2005a018, 2005a051
- 2 の山 (上から): 2005a047
- 3 の山 (上から): なし
となります。
次に return キーを入力すると、残りの 5 枚に対して
[2005a041 --> 1]
[2004c056 --> 2]
[2005a073 --> 2]
[2005c037 --> 1]
[2005a069 --> 1]
と表示され、
と音声ガイドが流れます。
これに従って紙を上から順に 1,2,2,1,1 の山に配ります。
つまり、これにより、
- 1 の山 (上から): 2005a069, 2005c037, 2005a041, 2005a093, 2005a074,
2005a018, 2005a051
- 2 の山 (上から): 2005a073, 2004c056, 2005a047
- 3 の山 (上から): なし
となります。
次に return キーを入力すると、
[1 回目終了]
と表示され、
と音声ガイドが流れます。
この通りに回収すると、上から
2005a069
2005c037
2005a041
2005a093
2005a074
2005a018
2005a051
2005a073
2004c056
2005a047
となります。
以下、同様に return を打って、指示通りに続けるわけですが、
以後、文字列と音声ガイドと山の状態のみ書きますと以下のようになります。
[2 回目開始]
(「2 回目開始」sortejun-05.wav)
[2005a069 --> 2]
[2005c037 --> 3]
[2005a041 --> 1]
[2005a093 --> 3]
[2005a074 --> 3]
(「2 3 1 3 3」sortejun-06.wav)
- 1 の山 (上から): 2005a041
- 2 の山 (上から): 2005a069
- 3 の山 (上から): 2005a074, 2005a093, 2005c037
[2005a018 --> 1]
[2005a051 --> 2]
[2005a073 --> 3]
[2004c056 --> 1]
[2005a047 --> 2]
(「1 2 3 1 2」sortejun-07.wav)
- 1 の山 (上から): 2004c056, 2005a018, 2005a041
- 2 の山 (上から): 2005a047, 2005a051, 2005a069
- 3 の山 (上から): 2005a073, 2005a074, 2005a093, 2005c037
[2 回目終了]
(「1 2 3 の順に、1 が一番上になるように重ねてください」
sortejun-08.wav)
この通りに回収すると、最終的に上から
2004c056
2005a018
2005a041
2005a047
2005a051
2005a069
2005a073
2005a074
2005a093
2005c037
となり、ソーティングが済むことになります。
ちなみに、この後 return を押すと、最終行なので
BOTTOM of the file.
と表示されますので q で shless を終了して終わりです。
今回は 10 枚なので、2 回はあまり早くないと感じますが、
80 枚位の紙でも大抵 3 回くらい (最悪は 4 回) で終わります。
なお、上の音声サンプルは、「れいしう」音声を使用してみました。
目次へ
(01/13 2007 更新)
先日、体調の影響か、右耳の聞こえ具合がやや悪くなりました。
近くの医者で診断してもらったのですが、
そこで受けた聴覚検査からふと思いついて、
yomi のツール (sndglis, sndchmix, wavconn) を用いて
簡単な周波数毎の聴覚テストを行ってみました。
これは、yomi のツールのデモにもなりますし、
聴覚能力を自分で測ってみたい、という人もいるかもしれませんから、
ここに公開することにします。
付属音声が大きくて全体で約 21MB もありますので、
付属音声を取り除いたアーカイブ (earch-nosnd-*) も用意しました。
yomi と tools ツールがインストールされていれば、
付属音声を自分で作成することもできます (作成スクリプトもあります)
ので、そちらを利用する方がいいかもしれません。
やることは簡単で、kterm などの上で
[01] [632.455Hz ~ 709.626Hz]
[02] [709.626Hz ~ 796.214Hz]
[03] [796.214Hz ~ 893.367Hz]
...
のように表示しながら、その音声データを順に再生するだけです。
各音声データには、表示される範囲の周波数を滑らかに変化する (いわ
ゆるグリッサンド)、1 秒の音が、
- 左右両方のチャンネル
- 左チャンネルのみ
- 右チャンネルのみ
の順に入っています
(正確に言えば、最後に同じ長さの無音も含まれています)。
つまり、ヘッドフォンをつけて実行すると、
最初は 632.455Hz から 709.626Hz までのグリッサンド音が
- 両耳から聞こえ、
- 次は同じパターンが左耳のみから聞こえ、
- 次は同じパターンが右耳のみから聞こえ、
- 最後は無音
で、次の音に移る、というようになっています。
- この最初の音のサンプル
u-01.wav
(705644 Byte; WAV 形式、量子化ビット数 16、2 チャンネル、
サンプリング周波数 44100Hz)
丁度、視力検査で段々見えにくい小さいものに移動していくようなイメージです。
最初に両耳から聞こえるものは、左右の耳のバランス
(厳密にはそれとヘッドフォンの左右のバランス)
が正常であれば真ん中から聞こえるはずですが、
右耳の聞こえが悪いようであれば、
それはやや左にずれて聞こえますし、
左右の聞こえ方の違いは、
その後の左のみと右のみの音声を聞き比べればよりはっきりすると思います。
検査は、人間の可聴範囲と言われる 20Hz ~ 20kHz の真ん中
(相乗平均である 632.5Hz) から 20Hz まで下降するもの、
又は真ん中から 20kHz まで上昇するもの、の 2 通りがあります。
その範囲をそれぞれ 30 分割してグリッサンドした音が用意されています。
なお、ハードウェア (コンピュータ、音声ボード、ヘッドフォン等)
の性能により、特定の範囲の周波数の再生に問題があることもあります
(特に最低音と最高音) し、
作成者には医学的な知識もなければ、
これで調べられるものの妥当性もわかりませんので、
あまりあてにはしないでください。
又、付属の音声データには、
20Hz から 20kHz、ボリュームレベル 0.7 のデジタル音が含まれていますが、
それを聞くことによって生ずる障害や損害には一切応じられませんので、
あくまで自己責任でご利用ください。
目次へ
(05/02 2008 更新)
「無限音階」というものを聞いたことがあるでしょうか。
音階をずっと上がっていくような単純な音 (和音) なのですが、
ある一定範囲を繰り返しているだけなのに、
なぜかそれの継ぎ目が聞こえなくて、無限に上がり続けているようなものです。
これは例えば以下にも記されています。
- 日本音響学会編「音のなんでも小事典」講談社 Blue Backs (P820)、1996 年、
「§37 無限に続く音階」(p127-129)
実際は、ドからその上のシまでの数オクターブの音階を和音にして、
その一番下のオクターブの音階をフェードイン
(つまりボリューム 0 から普通の音量へのクレッシェンド) で、
一番上のオクターブの音階をフェードアウト
(普通の音量からボリューム 0 へのデクレッシェンド) で重ねるようにすれば、
ごく低い音、ごく高い音は聞こえにくいので、
いつ入ったのか、いつ消えたのかがわからずに無限に続いているように感じる、
というものです。
これは、yomi-0.16 から付属されたクレッシェンド/デクレッシェンドツール
sndcresc と、sndhz (または sndglis), auconn, sndmix などを使えば作れます。
sndglis で、4 オクターブ、6 オクターブの無限音階を作成する方法と、
そのサンプルを紹介します。
- 4 オクターブの無限音階の作成手順:
sndglis C-2 C-1 6000 > sec0.au
sndglis C-1 C0 6000 > sec1.au
sndglis C0 C1 6000 > sec2.au
sndglis C1 C2 6000 > sec3.au
sndcresc -sv 0.0 sec0.au > sec0-c.au
sndcresc -ev 0.0 sec3.au > sec3-d.au
sndmix -v0.5 sec0-c.au sec1.au sec2.au sec3-d.au > waon-1.au
auconn waon-1.au waon-1.au waon-1.au waon-1.au waon-1.au > infty-4.au
そのサンプル:
- infty-4.au
(AU ファイル; 8000Hz mu-Law 1ch, 240032 Byte)
- infty-4.wav
(WAV ファイル; 8000Hz linear 1ch, 240044 Byte)
- 6 オクターブの無限音階の作成手順:
sndglis C-2 C-1 6000 > sec0.au
sndglis C-1 C0 6000 > sec1.au
sndglis C0 C1 6000 > sec2.au
sndglis C1 C2 6000 > sec3.au
sndglis C2 C3 6000 > sec4.au
sndglis C3 C4 6000 > sec5.au
sndcresc -sv 0.0 sec0.au > sec0-c.au
sndcresc -ev 0.0 sec5.au > sec5-d.au
sndmix -v0.4 sec0-c.au sec1.au sec2.au sec3.au sec4.au sec5-d.au
> waon-1.au
auconn waon-1.au waon-1.au waon-1.au waon-1.au waon-1.au > infty-6.au
そのサンプル:
- infty-6.au
(AU ファイル; 8000Hz mu-Law 1ch, 240032 Byte)
- infty-6.wav
(WAV ファイル; 8000Hz linear 1ch, 240044 Byte)
基本的には、いずれも以下のようなことをやっています。
- sndglis でドから上のドまでのグリッサンド音を、数オクターブ作成
(6000 ミリ秒)
- sndcresc で一番下のオクターブの音を 0.0 から 1.0 でクレッシェンドし、
一番下のオクターブの音を 1.0 から 0.0 でデクレッシェンド
- それらを sndmix で全部和音にして重ねる
- auconn でその重ねたものを数回 (上では 5 回) 反復する
最後の auconn で反復する際に波形が綺麗につながらない (位相のずれがある) ので、
若干繋ぎ目でノイズが入ります。
逆にそこで音としても本当は繰り返しが入っていることになっているのですが、
意外にそうは聞こえないと思います。
目次へ
(05/15 2019 更新)
ここでは、私が普段やっている読み合わせ作業の利用例を紹介したいと思います。
yomi 本体は perl で書かれていますが、
実は私は普段は awk と C シェルスクリプト使いで、perl はあまり使いません。
以下では、
awk と yomi と shless の組み合わせによる読み合わせの事例を紹介します。
例えば、以下のようなスペース区切りの学生の名簿のテキストファイル file1
があり (あえてやや難読名にしています)、
001 柏崎 一 カシワザキ ハジメ
002 工科 進助 コウカ シンノスケ
003 新潟 葉菜子 ニイガタ ハナコ
004 藤橋 都志江 フジハシ トシエ
このうちの 3 名のテストの点数が、番号と点数の組のファイル data1 が
あるとします:
004 90
001 82
002 75
このテストの点数の読み合わせをするために、data1 に
004 藤橋 都志江 90
001 柏崎 一 82
002 工科 進助 75
のように、通常は番号に対応する file1 の名前を追加して
読み合わせ作業をしているのですが、
単純にこのようなファイルにしてから yomi にかけると、
名前の難読部分を正しく読んでくれません。
名前の難読部分は、file1 のカナ部分を使えば正しく読めるはずなので、
私は一旦 file1 をまず以下の file2:
(004) フジハシ トシエ 90
(001) カシワザキ ハジメ 82
(002) コウカ シンノスケ 75
のようなファイルに変換してから、
それを「yomi -sh -d」にかけて、
shless 用の出力 file3 を作成しています。
なお、番号をかっこで囲むのは、一桁ずつ「ゼロゼロヨン」
のように読ませるためです。
しかし、この file3 をそのまま「shless -c +v file3」
のようにして読ませると、
画面表示は file2 のカナ表示の名前が表示されてしまいますが、
画面表示はむしろカナではなく、
004 藤橋 都志江 90
001 柏崎 一 82
002 工科 進助 75
の漢字表示の方が望ましいので、
file3 をさらに加工してこのような表示になるように
awk で変換をしてから shless にかけています。
手間はかかるようですが、一旦 C シェルスクリプトにしてしまえば
たいしたことはありません。
以下にその C シェルスクリプト例を紹介します。
#! /bin/csh -f
set awk = /usr/local/bin/gawk
## OS 付属の awk でも多分大丈夫
## file2 の作成
$awk -v db=file1 'FILENAME == db { seik[$1] = $4; meik[$1] = $5; next }\
{ printf "(%s) %s %s %s\n", $1, seik[$1], meik[$1], $2 }'\
file1 data1 > file2
## file3 の作成
yomi -sh -d file2 > file3
## file4 の作成
$awk -v db=file1 'FILENAME == db { seij[$1] = $2; meij[$1] = $3; next }\
/^\#shless:/ { gsub(/[)(]/, " ", $1); $0 = $0;\
$3 = seij[$2]; $4 = meij[$2]; print ; next }\
{ print }'\
file1 file3 > file4
## shless による読み合わせ
shless -c +v file4
実際にはここまで単純ではなく、
例えばデータベースにない学籍番号が data1 にあった場合のエラー処理なども
行っていますが、実質的にはこのような感じです。
これで、画面表示は「[番号] [漢字の姓名] [点数]」で、
音声出力はカナの方を読んでくれるような読み合わせが実現できます。
また、直接 yomi に読ませるのではなく shless にかければ、
enter を押すまで次の行に進みませんし、
前の行に戻ったり、今の行をもう一度読ませたりもでき便利です。
目次へ
- yomi 本体
(更新日 05/15 2019)
- 音声データ
(更新日 07/11 2004)
yomi 本体
音声データ
- 付属音声のいくつかの音を取り直したもの
(更新日 07/11 2004)
- こえうぇぶの音声データ
(更新日 02/18 2002)
目次へ
yomi のバグ情報や、yomi に関して頂いた情報、今後の計画など雑多なこと
をここに上げていきます。yomi をバージョンアップした際には、付属のド
キュメントに加えていきたいと思います。
- yomi version 0.18.1
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.18.0
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.17.3
- 12/18 2018
うちの日本語環境はいまだ EUC-JP で、
yomi の perl スクリプトも EUC-JP で書かれています。
そのため、および kakasi へのやりとりのためもあり、
yomi の perl スクリプトでは encoding モジュールを使用しているのですが、
最近の perl では encoding モジュールを使用しないように、
という警告がでるようになっていました。
それが、ついに perl 5.26 からは encoding
の使用がエラーになってしまいました。
よって、5.26 以降の perl で yomi を使用するとエラーとなって動作しません。
現在 5.26 以降の perl への対応を検討中ですが、
とりあえず 5.24 以前の perl であれば警告はでるものの使用はできます。
- 08/09 2018
yomi-0.17.3 を公開します。今回の更新は以下の通りです。
- shless に、最初に実行する行を指定するオプション -g[n]/+g[n] を追加
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.17.2
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.17.1
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.17.0
- 03/31 2017
yomi-0.17.0 を公開します。今回の更新はおおまかには以下の通りです。
- auconn (および yomi) に -C, -D (クレッシェンド、デクレッシェンド)
オプションを追加
- .auconnrc で length 等のオプションの初期値を設定できるように変更、
path, ext 行に CURLIST で前の設定を引き継ぐ形に変更
- auconn の -ip/-ie/-i オプションを廃止
- snddiff の追加 (デバッグ用)
- ソースコードの無駄な部分や書き方などを大幅に改訂
- auslcut, wavslcut, aiffslcut を sndslcut に統合し、
sox, awk, aufinfo を内部で使用していたのをやめる
(現在必要な外部プログラムは gnuplot のみ)
- tools コマンドのオプション、ソースコードの改良
tools コマンドのオプションの改良については、
付属ドキュメントの readme-tools を参照してください。
また、-C, -D オプションについては、
「yomi のサンプル」
の節にサンプルをあげておきました。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.16.1
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.16
- 05/02 2008
yomi-0.16 を公開します。今回の更新は以下の通りです。
- クレッシェンド/デクレッシェンドツール sndcresc を追加
- "contrib" を "tools" に変更
- sndvol のバグの修正
今回は、それほど大きな変更はないのですが、これまでは、
付属の音声編集ツールを「contrib」というディレクトリに入れるようにし、
そのインストールも今までは
"make install-contrib" のようにしていましたが、
これら "contrib" という名前をすべて
"tools" という名前に変更しました。
# "contribution" といっても、今のところ私だけなので (^^;
sndcresc は sndvol を少し変更して作ったもので、
音量レベルを最初と最後だけ指定して、
それに合うように線形に変化させます。
とはいっても、元の音量に指定した数値 (を直線補間した値)
を「かける」だけなので、
元の音が一定音程でなければ、
本当に音量レベルがその指定値になるわけではありません。
これは、無限音階でも作ってみようかと思ったときに
こういうものがないことに気がついて作ったものです。
その無限音階のデモは以下を参照してください。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.15
- 02/10 2007
yomi-0.15 を公開します。今回の更新は以下の通りです。
- auconn に検索パス順序切り替えオプション -P(r|s|o) を追加
- auconn にデフォルトの検索パス、拡張子リストの無効化オプション
-i(p|e|) を追加
- yomi にランダムパス選択オプション -R(n|s|w|e) を追加
- sortejun の bug の修正と、-o3 時の出力の改良
- その他いくつかの bug の修正
今回は、れいしうさんの音声の他のフリーの音素として
tspeech の付属音声を見つけたので、
音素データセットをランダムに選択するようなオプションを
auconn と yomi につけてみました。
tspeech については、yomi 付属文書の 2.7 節、または
以下をごらんください。
ついでに、yomi ではまだ対応していませんが、
特定の部分に特定の音素データセットを指定できるオプションを
auconn に実装 (-Ps,-Po) しました。
これを利用すると、例えば文章内の「」の会話部分の音声を、
地の文とは別の音声に切り替えたり、
会話の場合は、男声と女声に切り替えて読ませる、
などが可能になるかもしれません。
元々 yomi は、文章の読みにはあまり向いていないのですが、
「」内と地の文の読み替えだけならそう難しくもなさそうなので、
次期版では実装するか検討してみたいと思います。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.14.1
- 02/08 2007
sortejun のバグを見つけました。
最悪、core dump します (-o3 の場合)。
修正は行いましたが、
auconn や yomi のオプションの拡張も合わせて
yomi-0.15 として近々公開の予定ですので、それまで待つか、
または以下のパッチを当ててください。
このパッチは、単なるバグの修正だけではなく、
-o3 の際の音声出力部分の改変も行なっていて、上の
「sortejun のサンプル」
の節で紹介した音声出力に加えて、
最初に山の数、最後までにかかる回数、
最後は小さいのが上か (昇順) 大きいのが上か (降順)、
等も説明するように変更しました。
- 12/14 2006 (no.3)
kakasi は MS-Windows でも動きますし、
もちろん MS-Windows 用の perl もあります。
ということで、yomi が MS-Windows で動くようにできるかどうか、
少し検討してみたいと思います。
MS-Windows にはちゃんとした音声合成の仕組みがありますし、
それなりのソフトもありますのでほとんど意味はないと思いますが、
どちらかというと yomi 本体よりも、
yomi 付属のツール (contrib のもの) を MS-Windows で動くようにしたい、
と考えています。
- 12/14 2006 (no.2)
yomi では、現在デフォルトの音素と、
「こえうぇぶ」のフリーの音素を対象としていますが、
他にもフリーの音素を見つけました。
小松さんが、Emacs のキー入力に対してそれに対応する音を出力する
tspeech なるものを公開しておられます。
これに、田川さん作の、各キーに対応する音声がついています。
アルファベット音声はついていないようですが、
五十音、数字の音声などはありますし、
すべてが 1 種類の音声で録音されているわけではなく、
男性の音声もあれば女性の音声もあるようです。
これも yomi で使えるかもしれませんので、
後でその使い方をこのページ、
あるいは付属ドキュメントにまとめたいと思います
(実は、このテストをやっていて sndsmpl のバグに気がつきました (^^;))。
足りない音声は、デフォルトの音声ファイルを使うこともできるのですが、
これで最低 3 種類の音素が揃ったことになりますので、
それらをランダムに選択するオプションを作ってみると
どうなるかなとふと考えてみました。
そうすると、均一の音声ではなくなりますので
聞きにくくはなるかもしれませんが、
平板な読みではなくなりますし、毎回読み方が変わることになりますので
それなりにおもしろいかもしれません。
次期版として実現できたら、と考えています。
- 12/14 2006
yomi-0.14.1 を公開します。今回の更新は以下の通りです。
- yomi -ss の場合、"(12)" などの読みが
うまくいってなかった問題の修正。
- sndsmpl のバグの修正 (デフォルトでは正しく動作していませんでした)。
- 付属ドキュメントのバグの修正。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.14
- 08/30 2006
yomi-0.14 を公開します。今回の更新は以下の通りです。
- 元の文章にあるスペースを間とするオプション -ss ($SPACE1NULL) の追加
- 小さなバグの修正
オプション -ss について、少し説明します。
yomi はデフォルトでは、kakasi が生成する「間 (ま)」を元に
間 (ま) を持った読み上げを行います。
例えば、「読み上げを行います」という文章は、
「読み上げを」と「行います」の間 (あいだ) に間 (ま) を入れて、
それ以外の所には間 (ま) を入れずに読み上げます。
これは、yomi が内部で利用している kakasi が
% echo 読み上げを行います | kakasi -kH -KH -JH -s -f
読み上げ[よみあげ] を 行い[おこない] ます
のように、読み上げ」と「を」と「行い」と「ます」の
4 つの部分に分離していて、それを yomi の内部では、
「読み上げ」の後ろの「を」とをつなげ、
「行い」の後ろの「ます」をつなげる、という処理を行っていて、
そのブロック毎に短かい間 (ま) を入れているためです。
しかし、読み合わせ作業で人名などの固有名詞を読ませる場合は、
kakasi が妙なところで切るために妙な間 (ま) ができることがあります。
例えば、「新潟市」は「にいがたし」と読まれますが、
「柏崎市」は「かしわざき」と「し」の間 (あいだ) に間 (ま)
が入ってしまいます。
これは、kakasi が以下のように変換してしまうためです。
% echo 新潟市 | kakasi -kH -KH -JH -s -f
新潟市[にいがたし]
% echo 柏崎市 | kakasi -kH -KH -JH -s -f
柏崎[かしわざき] 市[し]
今回新設したオプション -ss を使用すると、
元の文にスペースが入っていなければそこには間 (ま) を入れず、
間 (ま) はスペースか句読点のところだけに入れるようになりますので、
例えば人名を姓と名に区切ってスペースを入れておけば、
オプション -ss によって今までのよりはそれらしく読むようになります。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.9
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.8
- 06/08 2006
yomi-0.13.8 を公開します。今回の更新は以下の通りです。
- contrib に sortejun を追加
- shless のバグ fix
sortejun は、テスト用紙のように、番号が書かれた紙の束を整列化
(ソート) するための補助ツールです。
auconn を使う shless 用の出力を生成して、
音声ガイドで紙の束の整列化を行うことも一応は可能です。
ただし、現在の番号の並びを入力する必要がありますので、
実用的かどうかはやや疑問で、よってデモツールのようなものです。
その動作原理や理屈については、以下をご覧ください。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.7
- 06/06 2006
0.13.7 で shless を改良したのですが、
バグ (以前の仕様とのずれ) が一つありました。
表示に余計に改行が出力されてしまいますので、
必要ならば以下のパッチを当ててください
(一番最後の方の改行を一つ取るだけなので手で修正しても結構です)。
次期リリースでは修正する予定です。
- 05/30 2006
yomi-0.13.7 を公開します。今回の更新は以下の通りです。
- contrib に snd2txt/txt2snd を追加
- shless の #shless: 行で \n (改行), \t (タブ), \N (行番号)
をサポート
最初のものは sox の .dat 形式のようなテキストデータ形式と
音声データとの相互変換のツールです。
音声データをそのテキスト形式に変換して解析することもできますし、
逆にその形式でデータを作って、それを音声化することもできます。
また、shless の改良は、
shless の各行毎の画面表示を複数行に拡張する仕組みです。
元々、紙のソーティング補助
(cf.
「紙の束の配分による整列化について」)
ツール用の仕様拡張ですが、
そのツールも後で contrib に入れるかもしれません。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.6
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.5
- 08/30 2005
yomi-0.13.5 を公開します。今回の更新は以下の通りです。
sndchmix は、多チャンネルデータからいくつかを選んで合成するツールです。
sndmix と違って合成時にレベル/ボリュームの指定はできませんが
(それは sndlevel/sndvol で可能)、sndchmix によって、
色んな合成処理が、中間ファイルなしにパイプで行えるようになりました。
例えば今まで 1 チャンネルのデータ a.au,b.au,c.au,d.au があったとき、
これを a+b を 1ch 目、c+d を 2ch 目にするには
% sndmix a.au b.au > tmp1.au
% sndmix c.au d.au > tmp2.au
% snstereo tmp1.au tmp2.au > file.au
のようにする必要がありましたが、sndchmix を使えば、
% sndstereo a.au b.au c.au d.au | sndchmix 1+2:3+4 > file.au
で済みます。つまり、再生できない仮想的な多チャンネルデータを経由して
sndchmix, shdchan を使うことで、
パイプライン向きの処理が行なえるようになりました。
これは、tbl2snd の複数グラフの音声処理にも役立ち、
例えば 8 本のグラフを音声化する場合、
1,2,3,4 個目のグラフは 1ch 目、5,6,7,8 個目のグラフを 2ch 目とするには、
% tbl2snd -m2 file.tbl | sndchmix 1+2+3+4:5+6+7+8 > file.au
でできるようになります。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.4
- 08/29 2005
yomi-0.13.4 を公開します。今回の更新は以下の通りです。
- contrib の sndchan を拡張
- contrib に、tbl2snd を追加
- AU ファイルの多チャンネル対応
- WAV に対する bug fix
sndchan は (psselect のオプションに似せて)
複数のチャンネルを取りだせるようにし、
AU でも多チャンネルが使えるようにしました。
これらは tbl2snd と関連した拡張です。
tbl2snd は gnuplot の 2D グラフを、table 出力を利用して音程で
表現する音を作成するツールです。
サンプルは
「gnuplot グラフの音声化ツール tbl2snd のサンプル」
をご覧ください。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.3
- 07/24 2005
現在の MacOS X は FreeBSD がベースになっているので、
色々な Unix のツールが動くのですが、
yomi もそれなりに動作するようです。
今年 4 月の「Mac Peaple」で yomi のインストールと使い方が
紹介されたようです。
水野貴明「X11 マニア; 第 16 回 日本語を読み上げる『yomi』」
Mac People, Apr. 2005, p120-121
さすがは Mac らしく音声形式は AIFF を使うみたいですし、
文字コードや改行コードを EUC で LF にしないとだめ、
という注意が書いてあるのも Mac らしいですね。
となると、MacOS X は標準では UTF-8 とかなんでしょうか。
- 01/13 2005
yomi のバグを見つけました。
「寝ちゃった」が「ねちった」と発音されます。
「ねちゃった」なら「ねちゃった」と発音されます。
これは、kakasi の処理した文字列を yomi が処理する時のバグです。
対処はできるかどうか分かりませんが、
時間のあるときに少し考えてみます。とりあえず報告まで。
- 01/05 2005
yomi-0.13.3 を公開します。今回の更新は以下の通りです。
- contrib に、mksnd1 (mksnd1.tcl,mksnd1) を追加
mksnd1 は、大学のオープンキャンパスで行なった
模擬実験で使った簡単なデジタル音声作成ソフトと
その GUI ラッパー (Tcl/Tk スクリプト) です。
詳しくは、付属のドキュメント (readme-contrib)、
及び 「スクリーンショット」
の節をごらん下さい。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.2
- 09/21 2004
yomi-0.13.2 を公開します。今回の更新は以下の通りです。
- 記号を読み飛ばすオプション (-sc/-nsc)、
アルファベットを読み飛ばすオプション (-sa/-nsa) を追加
これにより、視覚的な区切り記号やヘッダー情報が含まれるメールの読み上げも、
多少はまともに読めると思います。
もちろん、重要な内容を読み飛ばす可能性もあります。
今まではどうやってこれらを分かりやすく読ませたらいいか、
と考えていたのですが、ふと気がついて逆の発想で読まないように
できるようにしてみました。
文章の読み上げに使用したい場合はお試し下さい。
また、「いくつかの情報 (07/11 2004)」
に書いた録音し直した音声ですが、
あまり体調の良くない時期に録音したせいか、
かなり音が低くなっています。
体調が良くなった現在 (^^) 聞き直してみると、
割れている音よりもむしろ聞きづらくも感じます。
よって、付属音声は従来のままのものを付属させています。
割れている音は、また時間がある時に取り直ししたいと思います。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13.1
- 07/11 2004
yomi 付属音声を少し調べてみた所、
音が割れているものが含まれていることに気がつきました。
それらの音を取り直したものを
「音声データ」 の所に置きました。
次回のバージョンアップからはそれに変えるつもりですが、
なんでしたらこれと差し替えてみて下さい。
展開すると data/au, data/wav, data/aiff のディレクトリができて
その下に音声ファイルが含まれています。
yomi の音声をインストールしたディレクトリ
(/usr/local/share/yomi/data/ 等) のものと入れ換えれば結構です。
差し替えた音声ファイルは以下の通りです。
- 数字: 0,2,3,4,5,6,7,8,9,10,100,600
- アルファベット: A,K,Y
- かな: u,e,ki,ke,ko,sa,tu,ha,ya,go,za,ze,zo,da,de,do,ba,bi,be,bo,
pa,pe,po,fe,fo,hyo,ja,jo,pya,pyo,tsue,tsuo
正規化したときに雑音が大きくなった音がまだいくつかあるようなので、
それも時間のあるときに取り直しをしたいと思います。
- 06/07 2004
yomi-0.13.1 を公開します。今回の更新は以下の通りです。
- contrib ツールの bug fix (sndform,sndhz,sndglis)
詳しくは、以下の 2 種類の bug への対処です。
- 指定した通りの AIFF データが作成できない (sndform,sndhz,sndglis)
- infile 引数を指定できない (sndform)
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.13
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.12.4
- 03/21 2004
perl-5.8 の対応、Text::Kakasi に関して、
だいたいのテストは済みましたので、
なんとか春休み中に公開できそうなメドが立って来ました
(version 0.13 となる予定)。
ところで、「いくつかの情報 (03/11 2004)」
に書いた open2() を辞める件ですが、
- perl-5.8 でも、現状の open2() を使ったものはほぼそのまま動きそう
- なるべく yomi に必要なソフトは少なくしたい
(つまり Text::Kakasi を必須とするのは避けたい)
ということで、open2() を使うか Text::Kakasi を使うようにするかは、
インストール時に選べるようにしようかと思っています。
Text::Kakasi は jperl でも使えますので、
その選択は jperl か perl-5.8 かには無関係に選べるようにして、
つまり 4 通りの状態 (jperl+open2()/jperl+Text::Kakasi/
perl-5.8+open2()/perl-5.8+Text::Kakasi)
が選択可能な形にしようと考えています。
ただし、それらを option で選ぶ必要はなさそうなので、
- open2() を使うか Text::Kakasi を使うかはインストール時に決定
(yomi の先頭に書かれる変数等)
- jperl か perl-5.8 かは自動判別
という形式を現在は考えています。
お勧めの組合せは、まあ perl-5.8+Text::Kakasi でしょうか。
- 03/11 2004
perl-5.8.X への対応も少し調べてみたのですが、
まだよく use encoding の使い方を理解していないので、
もう少し時間がかかりそうですが、何とかなりそうな気がして来ました。
ところで、perl-5.8.X 対応版からは、kakasi の Perl 用モジュール
Text::Kakasi (2.X) を使用するようにするつもりです。
いままでは open2() を使って kakasi にパイプ入力したものの出力を
もらって使っていたのですが、
Text::Kakasi を使う方がずっと楽ですし、
open2() は使用があまり推薦されていないようなので、
open2() を辞める方向で考えています。
よって、yomi を使うためには Text::Kakasi を
インストールすることを仮定することになりますが、
jperl 版も相変わらず残してそちらでは open2() を使うままにするのか、
それとも jperl 版も Text::Kakasi にするか、その辺は少し迷っています。
何かご意見等ありましたらご連絡下さい。
なお、うちの環境では (Solaris 2.6, kakasi-2.3.4)、perl-5.8.3 上では
Text::Kakasi 2.04 は make test で失敗するテスト項目があるようです
(perl-5.6.1 や jperl5.00502 では問題なし)。
- 02/20 2004
そろそろ jperl から抜けて、新しい perl に対応しようと思ったのですが、
広く流布している perl-5.6.X と perl-5.8.X について少し調べてみると
どうも、perl-5.6.X では正規表現で日本語を使う方法がないようです
(jperl ももちろん 5.6.X 用のものはない)。
よって、perl-5.6.X に対応させるのは、かなり面倒そうで、
とりあえずは perl-5.8.X への対応を優先させて、
perl-5.6.X に関してはその後で考えてみたいと思います。
- 02/16 2004
更新したばかりの 0.12.4 ですが、Makefile* の最終行に改行がない
バグがありました (Thanks 山田栄成さん <hymd3a@plum.freemail.ne.jp>)。
次期バージョンで対応しますが、とりあえずは必要な Makefile の最終行に
手動で改行を入れて make してください。
- 02/10 2004
yomi-0.12.4 を公開します。今回の更新は以下の通りです。
- contrib の {au,wav,aiff}hz を sndhz に統合 (大幅な拡張を含む)
- contrib に sndglis を追加
今回は yomi 自体とはあまり関係ない contrib ツールに関する改変のみです。
sndhz は、以前の auhz, wavhz, aiffhz を統合した物ですが、
ついでにオプションを増やし、さらに
- 音長をブロック長でも指定可 (従来はミリ秒のみ)
- 音程を音名でも指定可 (従来は周波数のみ)
- 基本波形を正弦波/ノコギリ波/方形波から選べるように (従来は正弦波のみ)
のようにしました。
また、sndglis はお遊びツールですが、sndhz に少し手を入れて、
指定した 2 つの音程を滑らかにつないだ音 (グリッサンド) を
出力する物です。
これで、フォーマット依存のツールはほとんど統合できましたし、
また、別に作っていたものもほぼ contrib に取り入れることができました。
もう一つ、Tcl/Tk を利用した簡単な定数波形生成ツールがあるのですが、
これはもう少し見た目を調整してから (できたら次のバージョン位に)
追加したいと思います。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.12.3
- 01/25 2004
yomi-0.12.3 を公開します。今回の更新は以下の通りです。
- contrib の大幅な変更
- 付属音声ファイルの音量を level 0.7 に正規化
(付属ドキュメントには書き忘れました <(_ _)>)
- いくつか小さい bug fix。
yomi 自体に関係ある修正は後者 2 つの方ですが、
今回の大きな修正は最初の contrib の修正です。
ソースを大きく見直して、
- AU/WAV/AIFF を大半のツールで自動判別するようにする
- ツール等をたくさん追加
を行いました。中にはあまり意味の無さそうなもの (Ex. sndconmix) や、
お遊びのようなツール (Ex. sndrev,snddvrev) も含まれています。
多分、いずれのツールも sox の方が真っ当だと思いますが、
sox のようにたくさんのオプションがあって
オプション次第で何でもできるもの、というものとは別に、
オプションは少ない小さいツールの集まり、という形のものも、
ImageMagick と Netpbm の関係のように、
Unix ではそれなりの意味もあるのではないかと思っています
しかし、まだ総合してももちろん sox には全然かないませんので
期待はしないで下さい。
特に、FFT 等はまるでやっていないので
帯域フィルタ等の機能が丸でありません。
その辺りは今後の課題だと思います。
また今回気がついたのですが、周りの環境が全部そうなので
ソースではほとんどの部分で
(long int, int, short int, char) == (4byte,4byte,2byte,1byte)
であることを仮定して書いてあり、
そうでない環境ではまともには動かない可能性があります。
直さないといけないと思うのですが、これも今後の課題です。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.12.2
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.12.1
- 12/23 2003
今回の変更は、auconn (wavconn,aiffconn) に関するもので、
yomi 本体の動作とは関係ありません。
- auconn, wavconn, aiffconn のソースを統合し、
wavconn, aiffconn は auconn へのリンクとした
(コマンド名によって動作を変える)
- auconn の -L/-S オプションを、
音声ファイル名指定の途中でも指定できるようにした
(指定した後のファイルに影響)。
これによって、一つの auconn コマンドラインの途中で 1 音 1 音の
長さやスピード (音程) を変えたりできるようになりましたが、
yomi 自体にはそれに対応する変更はまだ入っていません。
よって、この機能を利用する場合は、yomi -d の出力を手 (か何か)
で修正することになります。
また、yomi に関連したツールで yomi の配付物には入れてないものが
多少あるのですが、それらや今後何か面白そうな物ができたら、
contrib/ の方に入れていきたいと思います。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.12
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.11.1
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.11
- 03/19 2002
今回の変更は
- yomi (auconn, wavconn, aiffconn) に -S オプション (倍速再生指定)
を追加
- れいしう音声ファイルの使い方をドキュメントに追加
- AUCONNOP, LASTNULLNUM をインストール時に Makefile で
指定できるようにした
- auhz, aiffhz, wavhz の HP-UX CC への対応
- aiffconn の bug fix.
です。-S オプションにより (-L オプションと組み合わせると)、
再生時の音程を全体的に変更できます。
ただし、例によって大したことをやっていませんので、
多少雑音が入る可能性があります。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.10.5
- 02/22 2002
下の
こえうぇぶのデータの
使用例ですが、以下のようにしてこれうぇぶデータ用の yomi を作る
という手もあります (WAV 0.25 秒の物を使う場合)。
- WAV 用の yomi を copy
# cd /usr/local/bin
# cp yomi-wav yomi-r250
- yomi-r250 の $AUCONNOP を以下のように書き換える
$AUCONNOP="";
==>
$AUCONNOP="-p/usr/local/share/yomi/data/reisiu-wav-250";
- 02/18 2002
こえうぇぶの
れいしうさんの音声データを yomi で使えるようにしたデータを
公開します。
こえうぇぶには色んな音階のデータがあるのですが、yomi の原理からして
それを使いこなすのは難しいので、
今回は一つの音階のデータについて
- そのデータの前後の無駄な部分を切り取って
- 長さを揃えて (0.18 秒の物と 0.25 秒の物)
- 音量を揃えて
- 足りないデータ (数字やアルファベット) を手作業でつなげて作って
- それでも足りないデータは無音へのリンクとして
いるだけです。
音階がほぼ一定なので、付属音声より機械的に聞こえますが、
こちらの音の方がずっと綺麗です。
データは音声データの種類 (AU,WAV,AIFF) ごと、長さごとにまとめたものを
置いておきますので必要なものを持っていって下さい。
利用例を簡単に述べます (WAV 0.25 秒のものを使う場合)。
- 適当なディレクトリに展開
# cd /usr/local/share/yomi/data
# gunzip -c ~/reisiu-wav-250.tar.gz | tar xvf -
- ~/.wavconnrc にそのディレクトリを設定
% cat ~/.wavconnrc
path /usr/local/share/yomi/data/reisiu-wav-250
ext :.wav:.WAV
nullfile null
これで WAV 用の yomi はれいしうさんの声でしゃべりだすでしょう。
- 02/14 2002
今回の変更は
- 主に FreeBSD 用に、音声データ列の最後が切れる問題の回避のために
ダミーの空データを付けることにして、その数を指定できるようにした
(-en [数], $LASTNULLNUM)
- Makefile.freebsd の WAV, AIFF の再生プログラムのデフォルトを
"sox で AU に変換して /dev/audio に流す" からそれぞれ
"waveplay を使う",
"sox で WAV に変換して waveplay を使う" に変更
- shless のコメント部分のバグ fix
です。最初の物は、
VZ-6000 + FreeBSD 4.4
で確認しました。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.10.4
- 12/25 2001
auconn, wavconn, aiffconn に音声ヘッダを出力しない -r オプションを
追加しました。
Solaris などで AU ファイルの出力で auconn の出力をデバイスに
リダイレクトするときに役に立つと思います。
ただし、yomi や Makefile にはまだこの変更を反映させていませんので
この機能を yomi で使うには (yomi で /dev/audio に直接出力している場合)
yomi の
$AUCONNOP = "";
を、
$AUCONNOP = "-r";
と修正して下さい。
なお、デバイス直接出力ではない場合は
音声ヘッダがないと正しく出力されない場合がありますので
-r は使わない方がいいかも知れません。
-r オプションの効果については、インストール後
% auconn A B C > /dev/audio
% auconn -r A B C > /dev/audio
(Solaris の場合は
% auconn A B C | cat > /dev/audio
% auconn -r A B C | cat > /dev/audio
)
の出力を比較してみれば分かると思います。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.10.3
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.10.2
- 11/02 2001
周辺のツールを少し修正しました。
変更点は以下の通りです。
- 音量のばらつきを正規化するためのツール
aunormal, wavnormal, aiffnormal を新規に追加しました。
- ある種の障害の元となっていた、音声ファイルの
カレントディレクトリの検索と拡張子なしの検索の優先度を下げました。
- shless のオプション、キーアサイン、先頭行最下行での挙動の変更と
先頭行が実行されないことの bug fix。
- ドキュメントに NEC EWS に関する記述を追加しました。
詳しくはドキュメントを
ご覧下さい。
なお、付属の音声データは音量の正規化は行なっていません
(ほとんど改善されないようです)。
れいしうさんのデータの音量の正規化はほぼ終りましたので、
後は yomi 用に足りないファイルの対応です。
次期バージョン (0.11) で対応予定です (ただしいつでるかは未定)。
shless は今までほとんど手を入れていませんでしたが、
今回 bug fix のついでに大幅に見直しました。
多少良くなったと思います。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.10.1
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.10
- 08/12 2001
- 現在、auslcut を使って久しぶりに音の切り出しをやっているのですが、
色々使いづらい点が見えて来ました。時間が取れたらまた改良したいと
思います。
なお、この切り出し時の auslcut のスクリーンショットを
作ってみました。
- auslcut の画面を見ていて思ったのですが、
私のツール類は結構オプションがたくさんつくものが多いです。
Tcl/Tk かなんかを使って、GUI の殻をかぶせてしまう、
ってのも手かなと思いました。
時間が取れたら考えてみようかと思います。
yomi は晴眼者、視覚障害者、両者のためのツールであることを
目指していますから、その精神には反しません。
- 04/04 2001
EWS4800 に関する追加情報です。
- /usr/bin/make を使う場合は、Makefile の g711.o:, ToFromIEEE.o:
で始まる行の次の行末にある "$<" をそれぞれ
"dist/g711.c", "dist/ToFromIEEE.c"
に変えて下さい。
- gcc でなく、OS 付属の CC でも通るようです。その場合 Makefile の
CC, CFLAGS などを次のように変えて下さい。
CC = /usr/abiccs/bin/cc
CFLAGS = -I/usr/abiccs/include
LFLAGS = -L/usr/abiccs/lib
LINK = /usr/abiccs/bin/cc
コンパイル時に error.h に関する warning がたくさん出ますが
無視して結構です (^^)
- yomi を使用する前に、例えば audiotool で何か音声ファイルを
再生しボリュームを調整しておいて下さい。
- 04/02 2001
新たに NEC EWS4800 マシンでも動作を確認しました。
詳しい情報は後程ソフト付属のドキュメントに載せることにします。
動作環境は以下の通りです。
- マシン: NEC EWS4800/320EX
- OS: EWS-UX/V 4.2
- perl: jperl5.005_03-990822 (これのインストールに苦労しました (^^;)
- kakasi: kakasi-2.3.2
- sox: sox-12.17 (必須ではありません)
- C compiler: gcc 2.7.2.3
- make: GNU make 3.75
ただし、以下の 4 点に注意が必要です。
- /usr/bin/make は標準の make とルールが違う所があるようで、
付属の Makefile では通りません。GNU make なら OK です。
Makefile の該当箇所を EWS-UX の make でも通るように書き直すのがいいのか、
Makefile を OS 毎に用意した方がいいのかについては、
少し考えてみたいと思います。
- 音声出力は、うちのマシンではまともに使えそうなのは SUN /dev/audio
互換のデバイス /dev/audio/au80u8m 位でした。よって、Makefile 内で
AUPLAY = "> /dev/audio/au80u8m"
WAVPLAY = "| sox -t wav - -r 8000 -U -c 1 -t au - > /dev/audio/au80u8m"
AIFFPLAY = "| sox -t aiff - -r 8000 -U -c 1 -t au - > /dev/audio/au80u8m"
のように指定しています (ただし雑音がかなり入ります)。
なお、OS 付属の再生コマンド mplay は、音声データとして
独自のヘッダーをつけた形式 (EWS4800 形式) を要求するので、
ラッパースクリプトを書いてその中で mconv で EWS4800 形式に変換、
とかしないと使えないようです。
- INSTALL は /usr/ucb/install, INSTDIR は /usr/bin/cp -r を使います。
なお、/usr/bin/cp には -R オプションはないようです。
- OS 標準の C compiler (/usr/abiccs/bin/cc とか) の方は
チェックしていません。
- 03/22 2001
yomi 0.10 付属の音声頭出しツールですが、残念ながら耳だけで使える、
というところまでは行っておらず、多少目で確認しながらの作業でないと
使いづらい点があります。その部分を改良したいと思っていますが、
なかなか時間が取れなくて (^^;
音声によるガイドをつけるのはちょっとうっとうしすぎるので、
音声ガイドでなく単純音によるガイドをつけようかと思っていますが、
何かもう少しいい手はないかと考えています。
- 03/04 2001
yomi のオプションを改良し、付属のツールを追加しました。
version 0.10 として公開します。変更点は以下の通りです。
- yomi が使用する音声再生ソフト、デバイス等の指示のためのオプション
-ap, -ao, -ad, -u を -ap に一本化
今までは、音声出力をデバイスか、再生ソフトかで分けてそれを -u で
指示していましたが、これは単に '>' (リダイレクト) にするか
'|' (パイプ) にするかしか行っていませんでしたし、
また、デバイスと再生ソフトの両方を別々の変数に分けて
保持していましたがこれも考えてみれば全く無駄でした。
よってこれを一本化し、
-ap '| [再生ソフト]'
-ap '> [音声デバイス]'
のようにすることにしました。
よって、インストール時の Makefile の修正方法 (デフォルトの値) が
今までとは若干違っていますので注意して下さい。
しかし、このようにすることで、色々なメリットが出ると思いますので
今までのよりは改善になっていると思います。
- CUI での音節データの頭出しツール auslcut (wavslcut, aiffslcut) の
追加、そしてそれに伴う単純音作成ツール auhz の小さい拡張と
wavhz, aiffhz の追加 (auslcut 等で使用)
前にアナウンスした CUI 環境での頭出しツールです。
gnuplot (version 3.7 以降) と sox (version 12.17 以降推奨) があれば
編集状況 (音声波形) をグラフで確認しながら作業することも可能です。
このツールは、2000 年度の 4 年生船橋崇将君の卒業研究による物で
彼との合作です。
- AU データディレクトリを WAV, AIFF データディレクトリに合わせて
まとめ直し (~/.auconnrc を作っている方は修正が必要になります)
今まで AU のデータだけ 50on/, num/, alpha/, null/ のディレクトリに
分かれていましたが、これを全部まとめて au/ にしました。
- いくつかの小さい bug fix
割と使える頭出しツールができたので、れいしうさんのデータの編集を
急ごうと思います。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.9.1
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.9
- 12/29 2000
下に書いた NAS の不具合ですが、開発版の最新版 1.4.1a では既に修正
されています。必要な方は
ここ (NAS Home page)
からダウンロードできます。
- 12/14 2000
付属ドキュメントでは、Solaris の環境での音声出力プログラムとして
OS 付属の /bin/audioplay を例示していますが、Solaris 2.6 付属の
このコマンドには小さい不具合があることが分かりました。
どうやら、音声データ部分が 3 バイト以下の場合、コマンドが終了し
ないようになっているようです。デバイス /dev/audio にそのような
データを直接流しても問題はないことから、このコマンドの不具合で
あると思われます。
- 11/19 2000
yomi バージョン 0.9 を公開します。今回の変更点は以下の通りです。
- yomi の画面表示は、今までは kakasi を通した後の行だったのに
対し、元々のファイルの行を表示するように改良
- '$' が読めていなかった bug の fix
- 正弦波音作成ツール auhz を追加
- kakasi の起動オプション ($KAKASIOP) に "-u" を追加
従来の表示形式を利用したい場合は -r を使えばできます。なお、
これにともない、shless でも元々の行の表示ができるようになっています。
見た目にはあまり大きな変更ではないようですが、yomi の動作の上では
かなり大きな変更になっていますので、バージョン番号を先へ進ませて
頂きました。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.8
- 11/18 2000
NAS (Network Audio System) に付属している再生ソフト auplay を
使って音を鳴らしている場合、auplay に渡す音声データファイルの
データ部分のサイズが丁度 40000byte であると、再生終了後に
auplay を抜けないというバグがあるようです (NAS 1.2p5)。例えば
version 0.7 以降の yomi を使っているのでしたら
% auconn -Lb8000+ a i u e o | auplay
とするとわかります。NAS のソースを見たのですがよくわからないので、
今の所対処法はありません (^^;
- 11/05 2000
「こえうぇぶ」に置いてある音素ファイルのうち、次の 2 つのファイルは
sox で変換しようとしてもできませんでした。
reisiuja_07_105zyo_44.aif
reisiuja_10_countdown.aif
調べてみると INST (instrument) chunk はあるが MARK (mark) chunk が
ない、ということのようでした。yomi バージョン 0.8 には aiffdiet と
いう不要な chunk を削除するツールがついていますが、これを使って
INST chunk を消してしまえば、普通に扱うことができるようになるようです。
- 11/05 2000
sox を使って音声データを AIFF に変換する場合は、sox の version に
注意してください。version 12.16 以前の sox は AIFF の書き出し
ルーチンにバグがありますので、version 12.17 以降の sox を使って
ください。そうでないと正常でない AIFF ファイルが作られます。
- 11/04 2000
yomi バージョン 0.8 を公開します。今回の変更点は以下の通りです。
- AIFF のサポート
- aiffconn, aiffsubstr, AIFF データを付属
- aufinfo の AIFF サポート
- WAV, AIFF データの不要な chunk の削除ツール (wavdiet, aiffdiet)
- WAV ファイルツールの WORD 境界に関する bug fix
- 若干ソースを整備 (特に aufinfo に関して)
- Makefile にインストール時の user, group の項目を追加
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.7
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.6.4
- 10/20 2000
yomi のドキュメントには、
漢字コードは EUC のみをサポート、と書いてありますが、実際には、
kakasi が複数のコードをサポートしているので、少し修正すれば
他のコードも使えると思います。
yomi に次の行が含まれています
$KAKASIOP = '-JH -kH -KH -Ea -s -f';
が、これに -oeuc を追加して
$KAKASIOP = '-JH -kH -KH -Ea -s -f -oeuc';
と修正すれば、多分他のコード (JIS, Shift JIS) も大丈夫だと
思います。
なお、kakasi のマニュアルによると、入力コードの自動判別は
完全ではないようですが、その場合は yomi の -ko オプションを
使って入力漢字コードを指定してあげてください。例えば Shift-JIS
の漢字が含まれたファイルの場合は
yomi -ko"-JH -kH -KH -Ea -s -f -oeuc -isjis" file
といった具合です。もちろん、nkf や qkc, coco などを使って、
あらかじめ EUC のファイルに直しておいても結構です。
将来 yomi のオプションとして、この入力漢字コードの指定を採用する
ことも考えておきたいと思います。
- 10/15 2000
音素データが存在しない場合、代用ファイルを指定してそれを使う
ことができるようにしました。環境変数、auconn (wavconn) の
設定ファイル、コマンドラインオプションのいずれかで設定できます。
代用ファイルは null.au (null.wav) などの無音のファイルでも良い
でしょうし、なんらかの警告音のファイルでも良いでしょう。
また、音声ファイルの情報を表示するツール aufinfo を作りました。
対応しているのは AU と WAV です。
以上をバージョン 0.6.4 として公開します。
- 10/15 2000
yomi では、今まで「でぃ」の音素はつけていましたが、使っていません
でした。それを使うようにしましたが、他にも現在は使っていない
「でぃぁ」「でぃぉ」の音素が含まれています。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.6.3
- 10/11 2000
ausubstr と同等のものの WAV 版 wavsubstr を作りました。ついでに
ausubstr の、length オプションを省略した時のバグを直してました。
バージョン 0.6.3 として公開します。
これで、「こえうぇぶ」のファイルを、WAV の形でカットする準備がで
きました。サンプルも更新します。
- 10/11 2000
ausubstr, wavsubstr を使うときは、編集する AU ファイルや WAV
ファイルのデータの情報、特にデータサイズが必要になります。ま
た、wavconn で連結できる WAV ファイルは同じデータ形式でないと
いけないので、そのデータの情報を調べる必要もあると思います。
それらのデータの情報を表示するツールを、そのうちに作ろうと思い
ますので、それまではそれらの情報は他のツールで調べてください。
- 10/11 2000
今まで、auconn, wavconn は、音素データが存在しない読みを含む
行に対しては連結を実行しませんでした。これを、そういう場合は
無音で代用することもできるようにすることを現在検討中です。
- 10/11 2000
「こえうぇぶ」のファイルは、音程が揃っているので、同じ音程の
音を使うと、非常に機械的なものになります。
「こえうぇぶ」にはいろんな音程のファイルがあるので、それらを
適当に組み合わせることでより自然にはなると思うのですが、
各単語に対するイントネーション辞書を作るとか、文法解析をする、
といった、あまり面倒なことはしたくないので、簡単に多少ごまか
す手はないかと考えています。
例えば音程をランダムにした場合はどんな風に聞こえるのか、
と思っているのですが、そんなオプションを作ってみようかと
思っています。
何かいい案がありましたら是非
教えてください。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.6.2
- 10/07 2000
yomi は、数字の読みは、例えば「300」(さんびゃく)、「800」(はっぴ
ゃく) のような、例外的な変化の読みにも対応していますが、
「10」(じゅう) が「じゅっ」に変化する場合 (例えば「十兆」) の読み
にはまだ対応していません。
- 10/07 2000
yomi は、-s なし (あるいは -ns) で実行すると、指定されたファイル
の最後まで実行しますので、その場合の中断は Ctrl-c などで行いますが、
環境にもよりますが、デバイスへの出力との関係で中断があまりうまく
いかない場合があります。
その場合、何回か Ctrl-c を繰り返すと止まるようですが、途中で中断する
可能性がある場合はできるだけ yomi の -s オプションを使うのがいいと
思います。-s を使うと、行毎に入力待ちになり、q RET で中断できます。
なお、q RET 代わりに、r RET で今の行を再び再生、単に RET で次の行へ
行きます。
または、付属の shless を使うという手もあります。
- 10/07 2000
数字、アルファベットを、専用音素を使用せず、全てひらがなに直して
ベタ読みするオプションを yomi に加えたバージョン 0.6.2 を公開しま
す。
これを使うとさらに聞きにくくなるのですが、例えば「こえうぇぶ」の
音素ファイルのように、アルファベット、数字の専用音素がない場合には
有効です。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.6.1
- 10/04 2000
「こえうぇぶ」にある AIFF (48kHz) の音声を、AU (μ-Law 8kHz) の
ファイルにしたら音質の劣化がひどくて使いづらい、と書きましたが、
これは、sox のバージョンをあげたら解消されそうであることが
わかりました。
いくつかのファイルには、ノイズが残るようですが、それの除去も
可能かどうか調べてみたいと思います。
今まで使用していたのは sox-12.12 (soxgamma), 今回バージョンアップ
したのは sox-12.16 です。これで、「こえうぇぶ」の音素ファイルを、
au 形式で利用できる見通しがたちました。
- 10/04 2000
ドキュメントにはまだ書いていませんが、yomi の使い方のうち、
やや複雑な例 (裏技 ?) として、次のようなものを紹介しておきます。
- yomi で、文章を音声化したファイルを作る
yomi では、-u0 で音声デバイスにリダイレクションすることができま
すが、その音声デバイスは -ad で指定できますので、例えば
% echo "新潟県" | yomi -u0 -ad niigata.au -q -
% echo "新潟県" | yomi-wav -u0 -ad niigata.wav -q -
とすると、「にいがたけん」という音声ファイル niigata.au,
niigata.wav ができます。ただし、これは 2 行以上の文章には
使えません (最後の文章だけがファイル化されます)。
- 読ませたい文書に必要な音声ファイルがあるかどうか確認
auconn (wavconn) には、必要な音声ファイルのパスを出力する
オプション (-l) が、チェック用についています。
yomi は、-ao で auconn にオプションを渡すことができますので、
それを使えば yomi 上でできます。ただし、この場合は、出力先を
デバイスなどから切り替えるために、-u1 で出力先をプログラムにして、
そのプログラム (例えば cat) を -ap で指定します。
例えば
% echo "新潟県" | yomi -ao-l -u1 -ap cat -
% echo "新潟県" | yomi-wav -ao-l -u1 -ap cat -
長い文章の場合は、更にその出力に sort と uniq などを噛ませると
いいでしょう。これは yomi がうまく動作しない場合のデバッグ作業
などで使えると思います。
もちろん、これらは yomi -d の出力を、手で編集しても可能で、
その方が速いこともあるかも知れません。
- 10/02 2000
Makefile にミスがあり、それを直したものを yomi-0.6.1 として公開し
ます。なお、yomi-0.6 とはそれ以外はバージョン表記程度しか違いませ
んので、手で修正、あるいは以下のパッチを当ててもらっても結構です。
yomi-0.6 と yomi-0.6.1 との差分 (3709 byte)
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.6
- 10/01 2000
音声ファイルとして WAV ファイルもサポートした yomi-0.6 を公開しま
す。付属の音声ファイルとして、元々つけていた AU ファイルを、単に
sox で変換したもの (linear 8kHz) をつけました。これで「こえうぇぶ」の
音素ファイルなどを利用する準備ができました。
- 10/01 2000
最初の 1 文字しか読まないバグ (auconn) は、Linux だけでなく、SUN
WorksShop C などでも発生する可能性があることが分かりました。現在の
version 0.6 では対応したつもりですが、まだそのようなことが発生する
ようでしたらご連絡ください。auconn -l a i u などとして a.au, i.au,
u.au のファイル (特に i.au 以降) のパスが正常に表示されなければその
可能性があります。
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.5.1
(「いくつかの情報」の先頭へ戻る)
- yomi version 0.5
- 09/28 2000
Linux (GNU libc) では、最初の 1 文字しか読まないことがあるバグが
ありました。
次期版で fix しますので、少しお待ち下さい。
長野大介さんには、このバグの報告や、Linux、音声ファイルの話や
色んなご意見を頂きました。どうもありがとうございました。
- 09/23 2000
下にあげた、こえうぇぶ
(れいしうさん作) の音素を使う件ですが、AIFF (48kHz サンプリング
16bit linear) のファイルを AU (8kHz サンプリング 8bit μ-Law) に
変換したら音質の劣化がひどくて、このままではやや使いづらいことが
わかりました。よって、AU 以外の音声データをサポートすることの
検討を始めました。
- 09/21 2000
単独の数字の "0" が読めないバグがありました。
次期版で fix しますので、少しお待ち下さい。
- 09/21 2000
yomi では、必要な音素を用意すれば、聞きたい音素でしゃべらせるこ
とが可能ですが、yomi-0.5.tar.gz に含まれているもの以外の音素
として、
こえうぇぶ(れいしうさん作)
のものを使わせてもらうことを現在計画しています。
大変ありがたい事にご本人からは使わせて頂くことを了承して頂き、
不足音素ファイル作成のご協力も申し出て頂いたのですが、
音素ファイルの編集作業にやや時間がかかりますので、公開はしばらく
お待ち下さい。
また、他に音素ファイルを作成したり、修正等された方がありました
ら、是非
こちらにご連絡下さい。
そして、できればこちらで公開させて頂ければ、と思います。
- 09/21 2000
この WWW page を独立させたとき、リンク先を間違えていて
yomi-0.5.tar.gz, readme-yomi-0.5 が見れなくなっていました。
アクセスされた方、申し訳ありませんでした。
- 09/19 2000
auconn のファイル検索順は、
path1/file.ext1
path1/file.ext2
path1/file.ext3
path2/file.ext1
path2/file.ext2
path2/file.ext3
....
とすべきでしたが、現在の版では
path1/file.ext1
path2/file.ext1
path3/file.ext1
path1/file.ext2
path2/file.ext2
path3/file.ext2
....
となっています。よって、カレントディレクトリ "." が
パスリストに入っていて (先頭でなくても)、たまたまカレントディ
レクトリに、例えば "mo" のような名前のファイル (また
はディレクトリ) があったりすると誤動作をします。次の版では修正
しますのでお待ち下さい。
「いくつかの情報」の先頭へ戻る
目次へ
ここには、yomi に関する Q and A をあげていきます。
(08/09 2010 更新)
1. うちの UNIX には auplay がないのですが
2. EsounD への対応は行なわないのですか
3. WAV への対応は行なわないのですか
4. MP3 への対応は行なわないのですか
5. Linux では動作しますか
6. kakasi が動けばどんな UNIX 上でも動作しますか
7. 音声読み上げではなくて点訳の方向は考えていませんか
8. 再生中にうまく中断できないのですが
9. 特定の音が読めないようなのですが
10. 音声の出だしに雑音が入るようなのですが
11. 付属音声データを他のソフトに流用したいのですが
12.
yomi でアルファベット列をローマ字読みさせることはできますか
13.
特定の単語に特定の読み方をカスタマイズするには
目次へ
A 1.
auplay は NAS (Network Audio System) に付属のコマンドで、多分標準では
インストールはされていません。
適当に AU ファイルを再生できる再生ソフトに読みかえてください。
なお、yomi version 0.6 からは WAV ファイル、
version 0.8 からは AIFF ファイルもサポートしています。
(01/08 2001; 10/30 2001 修正)
yomi に関する Q and A 先頭へ戻る
A 2.
他にもいくつかのフリーの音声ライブラリはありますし、OS に付属の
ライブラリがある場合もありますが、現在の yomi はいずれも使用して
いません。
それらを仮定すると、
yomi をインストールするにはそれらが先に
インストールされていないといけなくなりますし、
どんな貧弱な環境でも yomi を動くようにしたいので、
それらは使用しない形にしたいと考えています。
調べたりするのが面倒、というのも大きな理由です (^^;
(01/08 2001; 10/30 2001 修正)
yomi に関する Q and A 先頭へ戻る
A 3.
yomi version 0.6 からは WAV ファイルもサポートされていますので、
WAV ファイルが再生できる環境であれば利用できます。
(01/08 2001)
yomi に関する Q and A 先頭へ戻る
A 4.
まだ現在の所 (01/08 2001) 未サポートです。
(01/08 2001)
yomi に関する Q and A 先頭へ戻る
A 5.
日本語化された perl (perl5 用の jperl) か version 5.8 以降の perl
と kakasi (version 2.2.5 以上) がインストールされていて、
AU ファイルか WAV ファイル (yomi version 0.6 より) か
AIFF ファイル (yomi version 0.8 より) を再生できる環境であれば
Linux でも動作すると思います。
ただし、RPM などの Linux 用のパッケージは用意してはいませんので、
コンパイル、インストールの作業が必要になります。
詳しくは
付属のドキュメント
をご覧ください。
なお、perl-5.8.X には yomi version 0.13 から対応しています。
(01/08 2001; 03/23 2004 修正)
追加ですが、テキストファイルの漢字コードは現在の所 EUC-JP にしか
対応していません。
Fedora Core 1 の UTF-8 環境では segmentation fault が出る、
という報告がありました。
nkf 等であらかじめ EUC-JP に変換してから yomi に食わせて下さい。
(04/25 2004)
yomi に関する Q and A 先頭へ戻る
A 6.
UNIX 毎に多少サポートしている音声デバイスが違い、音声出力の
あたりは OS 毎にかなり違いがあるようですが、
- AU ファイルを鳴らすソフト
- AU ファイルを直接鳴らせるデバイス (/dev/audio 相当)
- WAV ファイルを鳴らすソフト
- AIFF ファイルを鳴らすソフト
のいずれかが使えるなら yomi は音声出力ができます。もちろん
日本語化された perl (perl5 用の jperl) か version 5.8 以降の perl が
もちろん必要です (perl-5.8.X には yomi version 0.13 からの対応)。
なお、yomi version 0.13 からは、内部で open2() で外部コマンドの
kakasi を実行する代わりに、
kakasi の perl モジュールである Text::Kakasi にも対応しています。
(01/08 2001; 03/23 2004 修正)
追加ですが、ソースでは大半のツールで
(long int, int, short int, char) == (4byte,4byte,2byte,1byte)
を仮定して書いてあります。
そうでないコンパイル環境 (OS、コンパイラに依存) では
まともに動かない可能性があります。
(01/25 2004)
追加ですが、テキストファイルの漢字コードは現在の所 EUC-JP にしか
対応していません。
Linux Fedora Core 1 の UTF-8 環境では segmentation fault が出る、
という報告がありました。
nkf 等であらかじめ EUC-JP に変換してから yomi に食わせて下さい。
(04/25 2004)
yomi に関する Q and A 先頭へ戻る
A 7.
次のような理由で、現在は考えていません。
- 視覚障害者の中で点字が使える人は必ずしも多くはない
- 点訳しても点訳されたものを打ち出したりするのに特殊なデバイスを
必要とする (点字プリンタ、点字ディスプレイなど)
- 必ずしも視覚障害者だけのためのソフトとは考えていない
- ひらがなへの変換は kakasi を使っているが、これで点訳をやるには
程遠い
ただし、例えば視覚障害者の中には聴覚障害も合わせて持っておられる
人もいます。不十分な機能でもいいから、特殊なデバイスを使っても
いいから点訳できるようにする、ということも確かに意味はあると
思いますので、今後の検討課題となるかと思います。
(01/08 2001)
yomi に関する Q and A 先頭へ戻る
A 8.
音声再生中は Ctrl-C などで中断しようと思ってもなかなか効かないことが
あります。yomi ではデバイスファイルを直接操作はしていないので、
原理的に中断は難しいです。よって、中断する可能性がある場合は、
yomi の -s オプションを使ってください。一行毎に終了するか
継続するか待つようになります (q RET で終了、r RET で今の行を再び再生、
単に RET で次の行)。
または付属の shless を使うという手もあります。
(01/08 2001)
yomi に関する Q and A 先頭へ戻る
A 9.
まず音声ファイルがあり、それを認識しているか調べて下さい。
例えば WAV ファイルで ka の音が読めないときには
% wavconn -l ka
としてみてください。それでインストール先の音声ファイルが
表示されない場合は音声ファイルのパスが正しく認識されていないか、
または別なファイルが認識されてしまっている可能性があります。
例えばドキュメントにも書いてありますが、
カレントディレクトリを検索する設定になっていて、
カレントディレクトリに "ka" のようなファイルかディレクトリがあると
それを音声ファイルとして使おうとして失敗します。
そのような場合は ~/.wavconnrc を設定してカレントディレクトリの検索を
しないようにして下さい。
なお version 0.10.2 以降ではカレントディレクトリの優先度は
下げられましたのでこのような障害は起こりにくくなったと思います。
(10/30 2001; 11/02 2001 修正)
yomi に関する Q and A 先頭へ戻る
A 10.
音声ファイルのヘッダ部分を出力しているためである可能性があります。
yomi version 0.10.4 からは auconn, wavconn, aiffconn で -r オプション
(ヘッダ部分を出力しない) が追加されましたのでそれをお試し下さい。
yomi でそのオプションを利用する場合はこちらを
ご覧下さい。
(12/25 2001)
yomi に関する Q and A 先頭へ戻る
A 11.
付属ドキュメントには以下のように書いてあります。
また、このソフトはフリーソフトとして公開します。
再配布、改良は可能ですが、その際、
このライセンス部分は改変せずに付属させてください。
改良は変更箇所を別途明記してください。ソースコードも、
dist/ 以下にあるもの以外の私が作成したものに関しては、
それを自由に使用して頂いて構いません。
付属する音声ファイルも、私が作成したものに関しては
自由に使用して頂いて構いません。
よって、音声データの利用に関しては以下のように考えています。
- yomi の配布物に含まれている音声データを
それだけ取りだして別のソフトに使用するといった使い方をする場合、
私的利用はもちろん構わないし、
自分のソフトに取りこんでそれを公開することも構わない
(再配布、再利用可)。
- このページで公開している、
「こえうぇぶ」の音声データを yomi で使えるように加工したものについては、
「こえうぇぶ」を運営しておられる、さかいれいしうさん
(http://reisiu.iamas.ac.jp/)
にも許可を得ること
「こえうぇぶ」の音声データについては、
加工したものの yomi 用としての公開は
さかいれいしうさんに許可を得ましたが、
それを他のソフトに再利用することに関しては許諾は得ていませんので、
上記のようにお願いいたします。
なお、ソフト付属音声はあまり音声品質はよくありませんので、
他の目的での利用に耐えるものかどうかはわかりません。
(01/13 2006)
yomi に関する Q and A 先頭へ戻る
A 12.
yomi は文書をひらがな列への変換で kakasi を利用しているのですが、
kakasi はアルファベット列をローマ字変換はできなさそうなので、
yomi 単独では無理です。
よって、sed などを使って、
アルファベット列をローマ字読みしたひらがな列への変換スクリプトを作って、
それで前処理するのがいいでしょう。
sed での変換はそれほど難しくはありません。
(08/09 2010)
yomi に関する Q and A 先頭へ戻る
A 13.
kakasi の辞書に単語を追加すればいいのではないかと思います。
詳しくは kakasi のドキュメントを参照してください。
または、sed などを使って、
そのような特定の単語をその読みに変換するスクリプトを作って、
それで前処理するという手もあります。
sed での変換はそれほど難しくはありません。
(08/09 2010)
yomi に関する Q and A 先頭へ戻る
目次へ
このツールの改良に関して、研究室の 1999 年度の 4 年生佐藤健美君に
色々調査、考察をして頂きました。どうもありがとうございました。
「こえうぇぶ」(「関連サイト」 参照)
を作成しておられるれいしうさんには、
yomi への音素の使用を快く了承して頂いたばかりでなく、
yomi には不足となる音素ファイルの作成のご協力まで申し出て頂きました。
本当にどうもありがとうございました。
長野大介さんには、Linux で yomi を使用する場合の問題点、バグリポート、
修正点、技術情報など、大変多くのことを教えて頂きました。
本当にどうもありがとうございました。
長野さん自身、yomi とは別のコンセプトのテキストファイルの
読み上げソフトを作成しておられます。こちらもお楽しみください。
(「関連サイト」 参照)
0.7 から 0.10 までの改良に関しては、研究室の 2000 年度の 4 年生
船橋崇将君に主にお世話になりました。
彼との意見交換の中での色々なアイデアが改良に使われていますし、
また、0.10 で取り入れられた CUI 環境での編集が可能な頭出しツール
auslcut, wavslcut, aiffslcut は彼の卒業研究によるもので、彼との合作です。
本当にどうもありがとうございました。
研究室の 2001 年度の 4 年生佐々木徹也君には、0.10.2 の yomi の
-L[bs] オプションのバグの報告を頂きました。どうもありがとうございました。
山田栄成さん <hymd3a@plum.freemail.ne.jp> には、
0.12.4 の Makefile のバグの報告、
Linux Fedora core1 + perl-5.8.3 での動作報告、
UTF-8 環境での問題の報告、その他のご意見等を頂きました。
どうもありがとうございました。
Sakae Kobayashi さん
(http://www.ksky.ne.jp/~sakae/)
には、0.16 の conf.c のバグの報告を頂きました。どうもありがとうございました。
その他、QandA に載せている yomi への質問などを頂いた方々、
どうもありがとうございました。
目次へ
目次へ
UNIX のページへ戻る
作成日: 05/15 2019
竹野茂治@新潟工科大学
(shige@iee.niit.ac.jp)