最近、gnuplot の開発版のドキュメントの訳の公開を怠けていました。 気がついたら半年も公開をしてませんでした。 訳の更新自体は月 1 位で続けているのですが、 最近は更新されるものも多くはなく、その油断もありました。 前回の公開は 2025-11-26 でしたが、その際の更新情報もあげておらず、 開発版の情報としては、 2025-07-31 のものが最後のようです。 となると 10 ヶ月位情報をあげてないことになります。
その間の更新情報はすべては把握していません。 とりあえずわかる分の主なものをあげてみます。
- パレット viridis と同族の名前付きパレット "magma" (新規)
- with labels {no}contours が追加された
- 試験段階の "for [<変数> in <配列>] が削除された
- multiplot のマウス操作、および多分 $GPVAL_PRE_MULTIPLOT, $GPVAL_LAST_MULTIPLOT の仕様の変更
- WebAssembly + WASI サポート
- set contourfill defined [zmin1:zmax1] color1, [zmin2:zmax2] color2, ... の追加
- VMS サポートの削除
- help の overview の追加
- gd.trm の gif animation の optimize オプションの削除 (新しい libgd が対応してない)
- sixeltek に {{no}transparent} {background <rgb_color>} のオプションを追加
- cairo.trm, gd.trm に関する修正 (点線/破線やパス描画の改善)
- mingw で ARM 上の Windows でのネイティブコンパイルを可能に
他にもいくつかあるようですが、詳しくは 本家 GIT サイトの History をご覧ください。
また、demo/ は、個々には小さな変更はあるようですが、 all.dem のラインナップには 2025-07-31 以降の変更はないようですので、 デモファイルを画像化したものをあげるのはやめておきます。
なお、「情報やメモ (02/19 2026)」 で紹介した、EUC-JP 環境で test を実行すると何やら大きな文字が出る件は 修正されたようで、現在は解消されているようです。
「情報やメモ (01/06 2026)」 に書いた、EUC-JP 環境で「年」を wxt terminal で表示させようとすると化ける、 という問題ですが、本家に報告したところ、 早速「set encoding eucjp」というものを作ってもらって、 EUC-JP 環境下ではそれでやってくれ、ということになりました。 現在の最新の GIT 版では「set encoding eucjp」または 「set encoding locale」で EUC-JP 対応になり、 「set title "2026年"」などが wxt terminal でも化けずに出るようになりました。 よって、EUC-JP 環境で使用している人は、 今後 .gnuplot に「set encoding locale」を入れておくといいかもしれません。
なお、今回の改良では、EUC-JP の日本語文字列内に、 GIT 版の gnuplot で利用できる "U+XXXX" 表記の Unicode 文字を混ぜてもちゃんと表示できます。 よって、EUC-JP 環境でも、本来は UTF-8 でしか記述できない Unicode 文字を混ぜることができるようになっています。
ただし、副作用もあります。実は、今回の改良で、test コマンドの出力が EUC-JP 環境では UTF-8 環境の場合、 および従来の gnuplot の場合とは違う結果になります。
test コマンドには、実は画面の真ん中あたりに 生の UTF-8 文字列を出力するデモが含まれています。 従来の gnuplot や、新しい gnuplot の UTF-8 環境であれば、 通常通り問題なくその UTF-8 文字列 (オングストローム記号 (U+00C5)、 → (U+2192)、∞ (U+221E) の UTF-8 列) が表示されます。 これは、 「情報やメモ (01/06 2026)」 にも書いたように、 従来の wxt terminal は UTF-8 文字列らしきものがあれば、 優先的に UTF-8 文字列だと思って適切に表示する、 という機能になっていたからです。
今回の変更では、その機能が変更されて、デフォルト encoding が取得できていれば、文字列はその encoding だと思って優先的に処理する、 ということになったので、EUC-JP 環境で test コマンドを実行すると、
Unable to convert "utf8: ": the sequence is invalid in the current charset (EUC-JP), falling back to iso_8859_1という文字列が表示されて、以下のような画像が出てしまいます。
- 新しい gnuplot の EUC-JP 環境での test コマンド (wxt terminal)
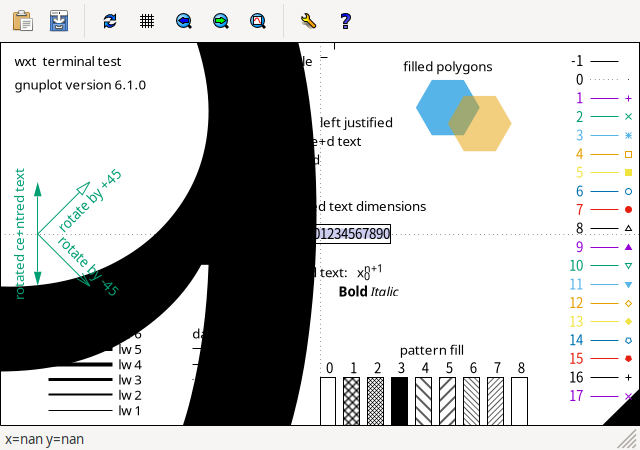
- 以前の gnuplot での test コマンド (wxt terminal)
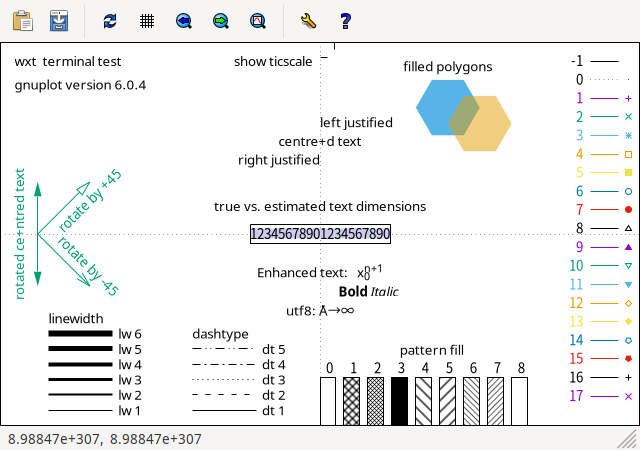
見てわかりますが、何やら大きな文字がかぶさっているように見えます。 よくわかりませんが、どうやらそのメッセージからして UTF-8 文字列を iso_8859_1 と見て表示しようとしたもののようです。 当然、事前に「set encoding utf8」としておけば問題ありませんが、 そもそも、test command で生の UTF-8 文字列が、 encoding の変更なしに呼び出されること自体が問題のように思います。 機会のあるときに、test コマンドを、UTF-8 文字列を呼び出す部分は、 encoding を強制的に utf8 にして、また元に戻す、 という形に変えられないか提言 (or patch の作成) をしてみたいと思います。
なお、個人的には、set encoding の中に EUC-JP は追加はしたくなかったのですが、 Ethan さんにサラサラと導入されてしまいました。 結果的には、まあある意味自然かなと思いますし、 U+XXXX で Unicode も出せるならまあ良かったかなとも思います。
(cf. 「情報やメモ (05/27 2026)」)
2,3 報告をします。
- wgnuplot のツールチップの文字化け
Gnuplot QandA 掲示板 にも書きましたが、 https://www.nagaoka-ct.ac.jp/ec/labo/visu/usb/tex2/gnuplot.shtml で報告されているように、最近の Windows 版の gnuplot で、 アイコンのツールチップの日本語が文字化けしています。
これは wgnuplot のバグですが、現在は修正済みで、 最新版の gnuplot-6.0.4 では解消されています。
- doc2web による HTML ファイルのバグ
最近の gnuplot の配布物には、gnuplot.doc から HTML 形式のヘルプ (例えば これ) を作成する doc2web.c というツールが付属しています。 しかし、これにバグがあり、トップページの gnuplot6.html の最初の方に HTML ページの終了タグ「</body></html>」 を書き出してしまっていました。 (例えば これ)
私が使っているブラウザでは問題なく表示されていたので気がつきませんでしたが、 もしかすると途中までしか表示されないブラウザもあるかもしれません。 開発版では修正されたので、今後改善すると思います。
- wxt terminal での文字化け (EUC-JP 環境)
私は、FreeBSD という Unix を使っていて、 日本語コードは UTF-8 や Shift_JIS ではなく、 Unix に伝統的な EUC-JP をいまだに使っているのですが、 wxt terminal で日本語文字列が化ける現象を見つけました。 多分 EUC-JP を使っている人はもうそれほど多くないと思いますので、 大半の人には関係ないと思いますが、一応情報をあげておきます。
wxt terminal はフォントの設定などをしなくても、 title などに日本語を使った場合、 適当な日本語フォントを使って日本語で表示してくれます。 ところが、EUC-JP の環境で、title や key などに「2025年」 (2025 の部分は半角) という文字列を表示させようとすると、 残念ながら「年」が化けてしまって「ǯ」になってしまいます。 「2025」と「年」の間に空白を入れてもだめです。
- 「年」を title と key で使用した文字化けする wxt terminal 出力
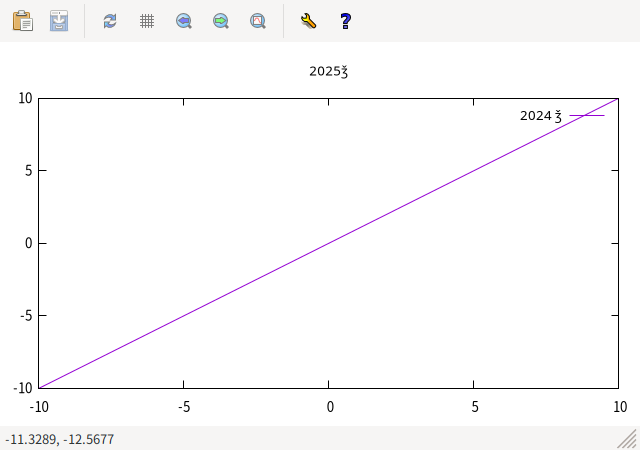
これは、「年」の EUC-JP のコードが 0xC7 0xAF という 8bit の 2byte コードで、それは UTF-8 文字列として <U+01EF> を表すものになってしまって、それでその Unicode 文字である 「ǯ」が表示される、というわけです。
これは、wxt terminal 用の C のプログラム (src/wxterminal/gp_cairo.c) に、文字列が UTF-8 とみなせるものであれば、 優先して UTF-8 として使用する、という部分があるためです。 それは、「set encoding」で何らかのエンコーディングを指定している場合でも 働いてしまうので、多分ある種のバグなのではないかと思います。
だから、少なくとも「set encoding」の設定がされている場合は、 そちらを優先するように修正してもらうようにしたいと思いますが、 現在の gnuplot の set encoding には EUC-JP の設定はありませんし、 「set encoding locale」も EUC-JP だと機能しないので、 EUC-JP の場合は「set encoding default」で問題が解消するようになれば、 と考えています。 現在より一つ手間が増えることになりますが、 常に発生する問題ではありませんし、 さほど大きな変更ではないと思います。
なお、とりあえずの回避策としては、「"2025年"」だと UTF-8 とみなされてしまうので、先頭に全角空白を追加して 「" 2025年"」と指定すれば UTF-8 とはみなされず、 他の日本語文字列同様 glib の機能で正常に EUC-JP 文字列として扱われて (UTF-8 文字列に変換されて) 正しく表示されるようになります。
- 先頭に全角空白を追加した回避策の wxt terminal 出力
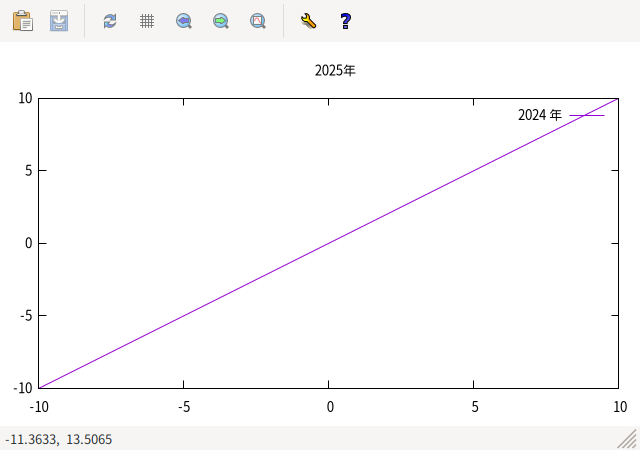
全角空白はどこか適当なところに入れれば OK です。
- 「年」を title と key で使用した文字化けする wxt terminal 出力
(cf. 「情報やメモ (02/19 2026)」)