書式:
stats {<ranges>} 'filename' {matrix | using N{:M}} {name 'prefix'}
{{no}output}
このコマンドは、ファイルの 1 列、または 2 列のデータの簡単な統計情報を
提供します。using 指定子は、plot コマンドと同じ形で解釈されますが、
index, every, using 指定に関する詳細については以下参照: plot (77)。
データ点は、その解析の前に xrange, yrange に従ってフィルタにかけられま
す。以下参照: set xrange (88.103)。その情報はデフォルトではスクリーンに出力さ
れますが、コマンド set print を先に使うことで出力をファイルにリダイ
レクトしたり、オプション nooutput を使うことで出力しないようにするこ
ともできます。
画面出力に加え、gnuplot は個々の統計情報を 3 つの変数グループに保存し
ます。
1 番目の変数グループは、どんなデータが並んでいるかを示します:
STATS_records |
N
|
範囲内のデータ行の総数 |
STATS_outofrange |
|
範囲外として除かれた行数 |
STATS_invalid |
|
無効/不完全/欠損データ行の総数 |
STATS_blank |
|
空行の総数 |
STATS_blocks |
|
ファイル内の index データブロック数 |
STATS_columns |
|
データ先頭行の列数 |
2 番目の変数グループは、1 つの列の、範囲内のデータの性質を示します。こ
の列は y の値として扱われます。y 軸が自動縮尺の場合は、対象とする範囲
に限界はありませんが、そうでなければ範囲 [ymin:ymax] 内の値のみを対象
とします。
2 つの列を同時に 1 回の stats コマンドで解析する場合は、各変数名に
"_x", "_y" という接尾辞を追加します。例えば STATS_min_x は、1 つ目の列
のデータの最小値で、STATS_min_y は 2 つ目の列のデータの最小値を意味し
ます。この場合、点は xrange と yrange の両方で検査することでふるいにか
けます。
STATS_min |
|
min(y)
|
範囲内のデータ点の最小値 |
STATS_max |
|
max(y)
|
範囲内のデータ点の最大値 |
STATS_index_min |
|
i | yi = min(y)
|
data[i] == STATS_min となる添字 i |
STATS_index_max |
|
i | yi = max(y)
|
data[i] == STATS_max となる添字 i |
STATS_mean |
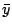 = =
|
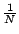 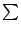 y y
|
範囲内のデータ点の平均値 |
STATS_stddev |
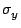 = =
|
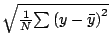
|
範囲内のデータ点の標本標準偏差 |
STATS_ssd |
sy =
|
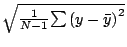
|
範囲内のデータ点の不偏標準偏差 |
STATS_lo_quartile |
|
|
第一 (下の) 四分位境界値 |
STATS_median |
|
|
メジアン値 (第二四分位境界値) |
STATS_up_quartile |
|
|
第三 (上の) 四分位境界値 |
STATS_sum |
|
y
|
和 |
STATS_sumsq |
|
y2
|
平方和 |
STATS_skewness |
|
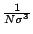 (y-)3 (y-)3
|
範囲内のデータ点の歪度 |
STATS_kurtosis |
|
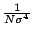 (y-)4 (y-)4
|
範囲内のデータ点の尖度 |
STATS_adev |
|
| y-|
|
範囲内のデータ点の平均絶対偏差 |
STATS_mean_err |
|
/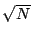
|
平均値の標準誤差 |
STATS_stddev_err |
|
/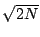
|
標準偏差の標準誤差 |
STATS_skewness_err |
|
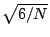
|
歪度の標準誤差 |
STATS_kurtosis_err |
|
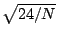
|
尖度の標準誤差 |
3 番目の変数グループは、2 つの列のデータの解析専用です。
STATS_correlation |
|
x と y の不偏相関係数 |
STATS_slope |
|
回帰直線 y = Ax + B の係数 A |
STATS_slope_err |
|
A の不確かさ |
STATS_intercept |
|
回帰直線 y = Ax + B の係数 B |
STATS_intercept_err |
|
B の不確かさ |
STATS_sumxy |
|
積和 (x*y の和) |
STATS_pos_min_y |
|
y の最小値を与える x 座標 |
STATS_pos_max_y |
|
y の最大値を与える x 座標 |
matrix が指定されていれば、using オプションは無視され、"z" 値のみ
が 1 次元のデータ集合として取り扱われます。その行列のサイズは、変数
STATS_size_x と STATS_size_y に保存します。
同時に 2 つ以上のファイルからの統計情報を使うことができれば便利でしょうから、変数のデフォルトの接頭辞である "STATS" をオプション name でユーザが指定する文字列に置き換えることができるようになっています。例え
ば、異なる 2 つのファイルのそれぞれの 2 列目のデータの平均値は以下のようにして比較できます:
stats "file1.dat" using 2 name "A"
stats "file2.dat" using 2 name "B"
if (A_mean < B_mean) {...}
STATS_index_xxx で示される添字の値は、plot コマンドの第 0 疑似列 ($0)
の値に対応し、最初の点は添字は 0、最後の点の添字は N-1 となります。
メジアンと四分位境界値を探す際はデータの値をソートし、点の総数 N が奇
数の場合は、その (N+1)/2 番目の値をメジアン値とし、N が偶数の場合は、
N/2 番目と (N+2)/2 番目の値の平均値をメジアン値とします。四分位境界値
も同様に処理します。
その後の描画に注釈をつけるためにコマンド stats を利用した例について
は、以下を参照してください。
stats.dem。
現在の実装では、X 軸と Y 軸の一方が対数軸の場合は解析できません。この
制限は今後のバージョンでは解消されるでしょう。
竹野茂治@新潟工科大学
2015年6月18日